- 更新日: 2020年02月06日
- 公開日: 2020年02月01日
PythonでGitHubのデータを自動集計する方法

Kotlin や Flutter が普及する中、相変わらず Java で Android アプリを作っている私。果たしてこのまま Java でいいのか...と、不安に... そこで Java や Kotlin、 Flutter(Dart)について情報を集める中、 GitHub のリポジトリ動向も参考になると判断。
しかし、 GitHubの言語別の統計データはなく、自分でデータ収集する必要が...
手作業でもデータ収集できるボリュームでしたが、せっかくなので Python でらくらく自動で GitHub 上のデータを収集できるプログラムを作りました。
「Web上にあるデータを簡単に収集したいな...」「Web上のデータを使ってこんなグラフ、資料作りたいな」と思うことがある方、参考になると思いますよ。
【今回ご紹介する内容】
・ GitHub API を使って 2018年1月から 2019年12月までの言語別新規リポジトリ数を集計
・ Webスクレイピングを使って GitHub からデータ収集しようとした結果...の顛末
GitHubのデータを自動で集計する方法
今回GitHubのデータから作成した表とグラフ

- Pythonプログラム(Google Colab)
- コードや作成したファイルなど GitHub
- 作成された CSV ファイル
Webからデータを自動で入手するための方法

今回は Androidアプリ開発と関連するプログラミング言語 "Java"、 "Kotlin"、 "Dart" を比較するために GitHub から情報収集しようと検討。 GitHub 内のデータを検索しようと思うと "キーワード検索" や "詳細検索*"、 それから "API" が存在。こうした環境を元に私達ができる情報収集のパターンは以下の通りでしょう。
- 手動で 1ページ 1ページ 確認してデータを記録(自動じゃありませんが...)
- Webスクレイピングを使って自動集計
- API を使ってデータ集計
- 誰かにデータ集計を依頼する
まず今回手に入れようとしているデータは、言語別の 2018年から現在までの新規リポジトリ数。数にすると 3 × 22 = 66、 66ぐらいのデータだったら自分で Webページにアクセスして集計する方法が早いようにも思えますが、言語が増えた時、期間が増えた時、他の人のことも考えた時、と考えるとプログラムで自動集計してくれる環境があったほうがいいかな、と判断。その結果が冒頭ご紹介したプログラムになります。
プログラムのモデルを考えて、コードを書いて、テストして、と手間はかかりますが、今後の安心につながりますし、自分自身への発展にもつながります。ちょっと遠回りに感じることも、やってみるとおもしろいですよ。
GitHubから月別新規リポジトリ数を集計する方法の選択

今 GitHub からプログラミング(Python)で言語別の新規リポジトリ数をゲットしようと決めました。次はデータ収集方法の選択ですが、プログラミングを使って Web上からデータを収集する方法は以下の 2パターンでしょう。
- API
- Webスクレイピング
幸い GitHub の API は充実していて、今回目的としている "リポジトリ数" も API でゲットできそう。ただ API は普段使わないので、ちょっと敷居が高そうなイメージ。それに対して Webスクレイピングは、 Python の基本と HTML、 CSS の知識があれば取り扱い可能。自分のレベルに応じた手法を用いればいいのですが、結論からいいますと、 GitHub で Webスクレイピングを使ったデータ集計はできません。 10回ぐらいプログラムから GitHub にアクセスすると "BAN" されます。
まずは API を使ったデータ集計からご紹介し、あとで "BAN" されるプログラムもご紹介したいと思います。
! GitHub では Webスクレイピングできませんでしたが、制限をかけていないサイトでデータ収集する時は Webスクレイピングが有効です。
GitHubのAPIを使ってPythonでデータ収集する全体イメージ

(クリックで拡大) GitHub API でリポジトリ数を集計する全体フロー
今回は GitHub の API を使ってリポジトリ数を集計、というミッションですが、やり方はいくつかあると思います。今回は一例としてご参考下さい。
まず確認しないといけないことがありますのでリストアップします。
- 最終的な完成形のイメージ
- APIの様子
- 開発環境
どの順番からでも大丈夫ですが、上記内容を確認しておく必要があるでしょう。今回は上図のようにまずは完成形のイメージから行いました。
どこまで完成形イメージに近づけられるか分かりませんが、とりあえず必要なデータの項目は確認しておく必要があるでしょう。例えば今回の場合であれば、『プログラミング言語』 『日付』 『リポジトリ数』。

そして API の様子は、 GitHub API トップページ より今回目的である「リポジトリ」の項目か「Search *」の項目か悩むところ(上図参照)。
内容を確認したところ 「Search *」 の方が妥当と判断し、こちらを使うことに。サンプルの URL にアクセスしてみると、 JSON形式のデータが返ってきます。
サンプルURL https://api.github.com/search/repositories?q=tetris+language:assembly&sort=stars&order=desc

ページトップに合計値(total_count:)と記載されていて、今回取得したいレポジトリ数も total_count: として取得できそうな予感がしますね。ただサンプルの API URL は、アセンブリ言語をつかったテトリスのリポジトリ数。今回は Dart や Kotlin、 Java それから期間指定でデータを取得したい目的があります。 "API" というと特殊感がありますが、こんな風に普通に Webで確認できる内容のモノもあります。そして サンプル API の URL をよく見ると、 URL の文字列で内容を制御している感じがしますね。
GitHubのAPIのURLを決める方法

先ほど GitHub の API サンプルを使った結果、 "URL" によって出力結果を制御していることが分かりました。この API の URL をベースに、"言語" と "期間指定" ができれば良さそうな感じ。しかし、どんな風にそれらの値を URL にセットしたらいいか、分かりませんよね。この答えのヒントは、 GitHub の詳細検索画面にありました。
上図左が詳細検索画面で、右側がその検索結果の様子。検索結果の URL を確認すると、先ほどの API のような感じで "言語" や "期間" が指定されている様子が確認できます。
検索詳細画面のURL
https://github.com/search/advanced
検索結果のURL
https://github.com/search?utf8=%E2%9C%93&q=created%3A2018-01-01+language%3ADart&type=Repositories&ref=advsearch&l=Dart&l=
APIのURL
https://api.github.com/search/repositories?q=tetris+language:assembly&sort=stars&order=desc
試しに詳細検索結果のURLの一部分を API の URL にくっつけてみます。すると先ほどの詳細検索結果と同じ内容のデータが API で取得できました。
アレンジした API URL https://api.github.com/search/repositories?q=created%3A2018-01-01+language%3ADart

https://api.github.com/search/repositories?q=
をベースURL にし、あとのパラメーターは詳細検索画面のURLを流用すればOKという感じ。言語、期間以外にもスター数やライセンス条件など設定して任意のレポジトリ情報を確認できますね。先ほどアレンジした API URL は、 2018年1月1日の Dart の新規リポジトリ数でしたが、 2018年1月分の月間データが取得できるかテスト。
https://api.github.com/search/repositories?q=created%3A2018-01+language%3ADart

日付の URL を 2018-01-01 から 2018-01 に変更しただけで 2018年1月分の Dart を使った新規リポジトリ数が取得できました。この URL をベースに、 Python のループ処理で 日付、 言語 を制御すれば設定した期間、言語のリポジトリ数が自動で集計できそうですよね。
GitHubのAPI値をPythonで取得する方法
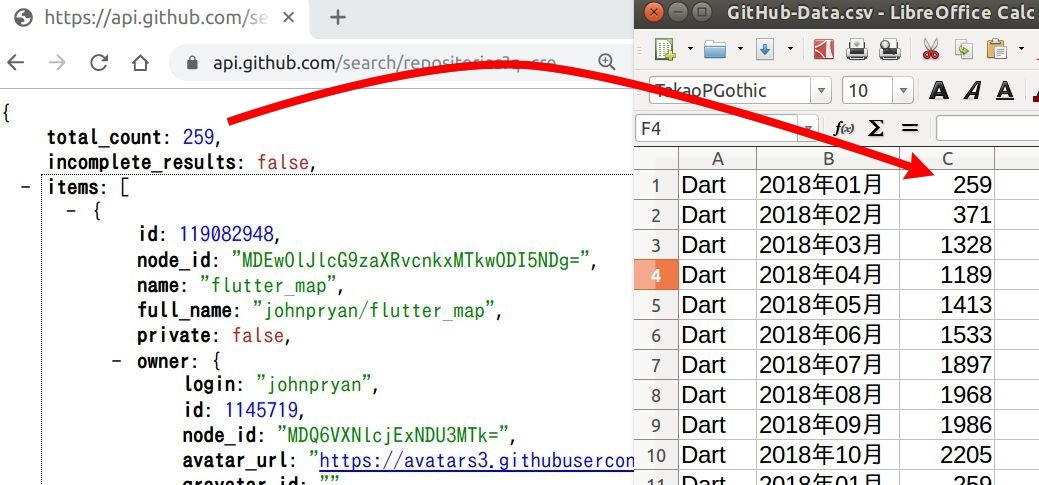
先ほど GitHub の API を使って、今回欲しい Dart の 2018年1月分のリポジトリ数を確認できました。
API URL https://api.github.com/search/repositories?q=created%3A2018-01+language%3ADart
次はブラウザ上に表示されるリポジトリ数を、どうすれば "データ" として入手、管理できるかということ。コレには PHP や Ruby、 JavaScript などの言語でも対応できると思いますが、今回は Python を使って処理を進めてみました。
Python...パソコンに Python の実行環境があれば問題ないですが、 Python 入っていなかったり、 スマホで本稿を閲覧中の方もいらっしゃるでしょう。そんな時はブラウザ上ですぐに Python を実行できる Google Colab が便利です。
試しに上記 URL にアクセスしてみて下さい、今回の目的であるリポジトリ数が収集できる Python プログラムが既にセットされています。そして ランタイムを実行すると Python を動かして、 CSV データを 10分ほどでゲットできます。
さて開発環境から話を元に戻して、ブラウザ上のデータ(APIデータ)をどうすれば取得できるか、という問題。この問題は Python の便利なモジュールやライブラリ群を使うと解決できます。

上記画像のPythonコード
import requests
response = requests.get("https://api.github.com/search/repositories?q=created%3A2018-01+language%3ADart")
type(response)
response.text
type(response.text)
import json
data = json.loads(response.text)
type(data)
data
print(data["total_count"])
上図はブラウザ上のデータ(APIデータ)を取得するまでのコード。一つずつ内容を確認して実行しているために、少し行数が多くなっています。
まず Python コードで Web に接続するために requests という Python モジュールを使用。 response = requests.get("・・・・・") の部分で出力結果として <Response [200]> が返ってきています。これは Web への接続完了、という合図。 requests をアプリケーションに使用する場合などは、 <Response [200]> 以外に <Response [500]> などの接続エラー時の処理プログラムも必要になりますが、記述量が増えますの今回は "なし" で進めていきます。
そしてその後 response.text でアクセス先の内容を取得。ただ response.text で取得できるデータは "文字列"。 今回目的とするリポジトリ数をこの文字列から獲得しようと思うと、スライスなどのテクニックなると思いますが、リポジトリ数が 1000 とか 20000 など桁が上がってくると正確に取得できない可能性が出てきます。
この問題は、アクセス先の Web ページを JSON形式で読み込めば OK。
import json
data = json.loads(response.text)
とすることで、先程は文字列で読み込まれていた Webページの内容が "辞書型(dict)" で読み込まれていることが確認できます。試しに Webページの内容を辞書型(タプル)で読み込んだ data の値を出力してみましょう。

先ほどの response.text だけの時とは違って、体系的にデータが表示。すごく長い内容ですが、一番下の方に 'total_count': 259 があります。しかし、この JSON データ見難いですよね。とりあえずどんなデータが格納されているかということを確認するためには .key() が便利。data.keys() とすることで JSONデータの "キー" 部分を確認できます。お目当ての 'total_count' もあることが確認できますね(下図参照)。

あとは キー 'total_count' の要素を確認するためのコード data["total_count"] を実行すれば、 'total_count' とセットになているデータを獲得することが可能に。あとはこのリポジトリ数を CSV に書き込めれば OK。
まとめ: GitHubのAPI値をPythonで取得する方法
GitHub の API アクセス先を JSON 形式で読み込み、キーを指定することでリポジトリ数を獲得できた。
PythonでCSVファイルにデータを書き込む
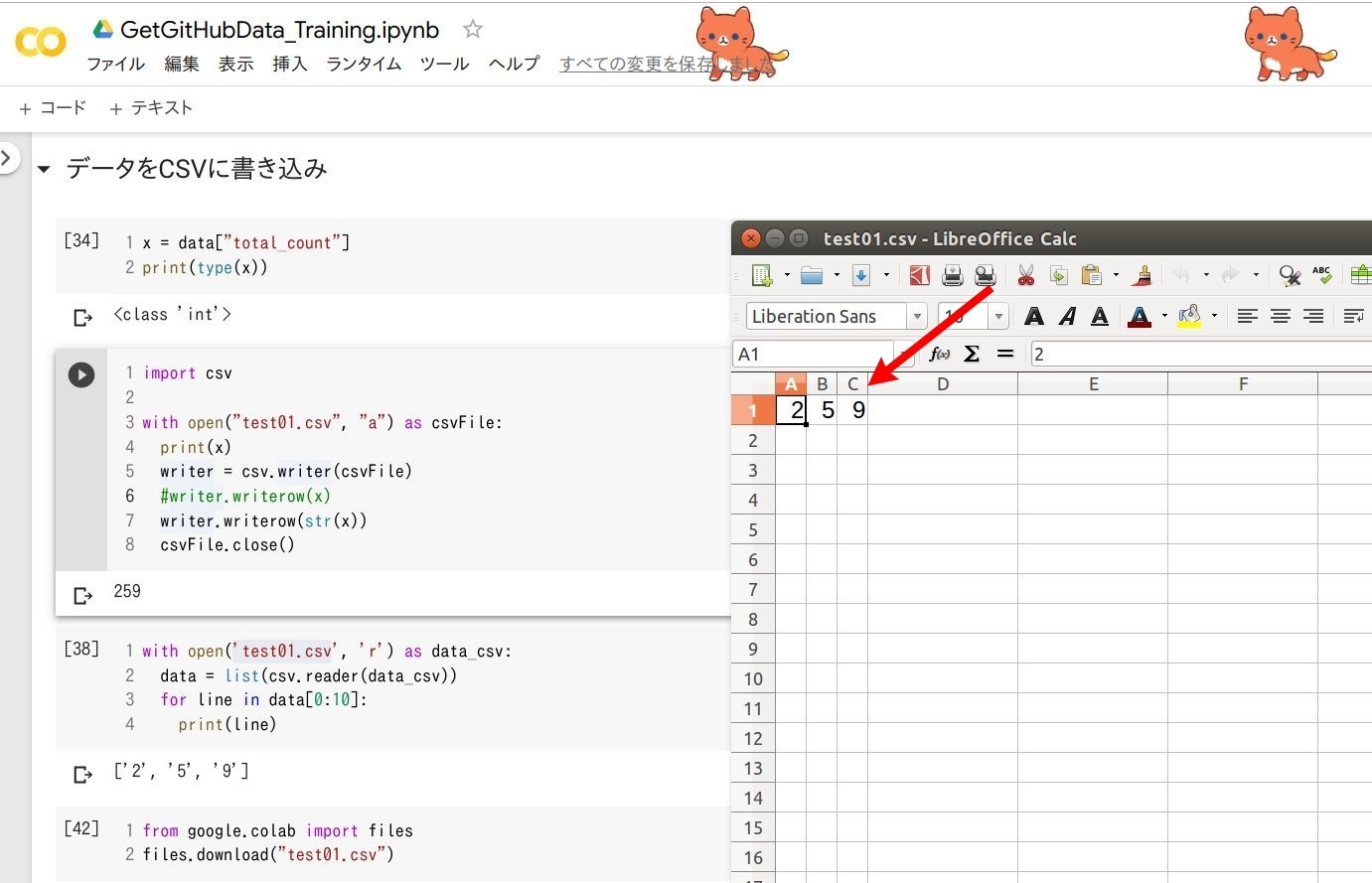
上記画像のPythonコード
x = data["total_count"]
print(type(x))
import csv
with open("test01.csv", "a") as csvFile:
print(x)
writer = csv.writer(csvFile)
"""writer.writerow(x)"""
writer.writerow(str(x))
csvFile.close()
with open('test01.csv', 'r') as data_csv:
csv_data = list(csv.reader(data_csv))
for line in csv_data[0:10]:
print(line)
from google.colab import files
files.download("test01.csv")
今回は獲得する GitHub のリポジトリ数をデータ加工しやすい CSV ファイルに保存していきます。 Python で CSV ファイルを作成し、データを追加していく様子は上図の通りですが、 出来上がった CSV ファイル、ちょっとイメージと違いませんか。リポジトリ数を示す 259 という値が、 2, 5, 9 とバラバラになってセルに保存されています。これは CSV にデータを書き込む際に 259 のデータ型を int(数値) から str(文字列) に変えているため。 int のまま CSV にデータを書き込めればいいのですが、そうもいかない様子...
このデータがバラバラになってセルに保存される問題、以下のように書き込み指示を csv.writer() を csv.DictWriter() に変えれば OK。

上記画像のPythonコード
print(type(data))
print(data["total_count"])
x = data["total_count"]
print(type(x))
with open("test02.csv", "a") as csvFile:
fieldnames = ["count"]
writer = csv.DictWriter(csvFile, fieldnames=fieldnames)
writer.writerow({"count":x})
csvFile.close()
with open('test02.csv', 'r') as data_csv:
csv_data = list(csv.reader(data_csv))
for line in csv_data[0:10]:
print(line)
from google.colab import files
files.download("test02.csv")
まず結果を確認すると、先程はバラバラのセルに保存された 259 が一つのセルに保存されています、いい感じですね。 CSVへの書き込みが改善された理由としては、標準の書き込みモード csv.writer() から csv.DictWriter() の辞書型の書き込みモードに変更したため。 259 という数値型の値をキー count に割り当てることで、数値型のまま CSVファイルにデータを書き込み。
ライブラリなどを使えばもっと簡単にデータ操作できると思いますが、あえて Python の標準ライブラリで CSV に書き込みを行ってみました。
今回のメインであるリポジトリ数を CSV に書き込むことができました。あとは "言語" と "期間" を指定して、順番にそのリポジトリ数をゲットできるようにループ処理すれば良さそうですね。
まとめ: PythonでCSVファイルにデータを書き込む
Pythonで CSV にデータを書き込む際は文字列型を要求される。 CSV への書き込み方式を csv.writer() から csv.DictWriter() に変更することで解決できた。
GitHubのAPIをループ処理して毎月のリポジトリ数をゲットする

上記画像のPythonコード
import json
import requests
import csv
import time
year = ["2018", "2019"]
month = ["01","02","03","04","05","06","07","08","09","10","11","12"]
language = ["Dart","Kotlin","Java"]
for l in language:
print(l)
for y in year:
for m in month:
check_point = y + "年" + m + "月"
print(check_point)
""" https://api.github.com/search/repositories?q=created%3A2018-01-01+language%3ADart """
""" https://api.github.com/search/repositories?q=created%3A" + 2018-01 + "+language%3A" + Dart
url = "https://api.github.com/search/repositories?q=created%3A" + y + "-" + m + "+language%3A" + l """
response = requests.get(url)
data = json.loads(response.text)
x = data["total_count"]
print(x)
with open("GitHub-Data.csv", "a") as csvFile:
fieldnames = [ "Language", "date", "count"]
writer = csv.DictWriter(csvFile, fieldnames=fieldnames)
writer.writerow({ "Language":l, "date":check_point,"count":x})
csvFile.close()
time.sleep(7)
今回はなるべくシンプルなコードでデータを獲得するために、 CSV へのデータ保存は、
| セル1 | セル2 | セル3 |
| プログラミング言語 | 年月 | リポジトリ数 |
としました。結果的に上図のような形で CSV に保存されて、グラフなどを作成する場合はデータ・セルの移動が必要になるかもしれませんが、 Pythonコードのシンプルさを優先しました。また今回は一つ一つのセルの値を変数で管理しますが、 Numpy などの配列テクニックを使うともっとスマートなコードで記述できると思います。何度も言うようですが、シンプルな簡単な Python コードの記述に努めました。
さて毎月の言語別のリポジトリ数をゲットする、ということで上記コードを書いていますが、どうでしょうか、イメージできますでしょうか?上のコードのループ処理を可視化すると、以下のような感じで回っていることが確認できると思います。

まずプログラミング言語: Dart を選択して、 2018年1月から2018年12月までをクロールし、2018年が終わったら 2019年1月から2019年12月までクロール。それが終わればプログラミング言語を Kotlin に変更し、先ほどと同じように 2018年1月から2018年12月、そして 2019年というクロール内容。
また各月、各言語のリポジトリ数は API URL の変更によって制御。本稿最初の方でご紹介した『GitHubのAPIのURLを決める方法』が参考になると思います。上図コード内にも書かれていますが、 Dart の 2018年1月 のリポジトリ数は、
"https://api.github.com/search/repositories?q=created%3A2018-01+language%3ADart"
で確認できます。上記 URL を "年月" と "言語" の部分で区切ってみると以下のように。
"https://api.github.com/search/repositories?q=created%3A" + 2018-01 + "+language%3A" + Dart
2018 、 01 、 Dart という 3箇所を順番に変更できるようなループ文を書けば、各言語の各月のリポジトリ数をゲットできそうですね。年月の取り扱いには datetime などのモジュールもありますが、今回は "年" と "月" それぞれを配列 year と month に格納し、言語は language に格納。
あとは順番にループ処理してくれるように
for l in language:
for y in year:
for m in month:
API URL 作成
APIにアクセス
リポジトリ数ゲット
CSVへの書き込み
とすればOK。上記のループ・プログラムで 言語 -> 年 -> 月 の順番で GitHub API の URL を作成。そして URL にアクセスし、 リポジトリ数をゲットし、 CSV に保存。完了すれば翌月に移動し、 12月まで繰り返す、という内容。 各月の URL の作成やリポジトリ数のゲット方法、 CSV への書き込みは今までご紹介してきた通りの内容です。
ただし、上記のループでプログラムを実行すると、ものすごいスピードで API URL を作成し、 URLにアクセスし、リポジトリ数を取ろうとします。この行為を受けた GitHub側のサーバーは異常なアクセス状況を検知し、ブラウザへのアクセスを制限。
【GitHub へのアクセス多過で表示されるエラー】
Traceback (most recent call last):
File "local-python.py", line 21, in <module>
x = data["total_count"]
KeyError: 'total_count'
エラー内容は、 total_count がないよ、ということですが、 GitHub へのアクセス制限はこちらに書かれています。

the rate limit allows you to make up to 10 requests per minute.
と記載がありますね。つまり API URL へのアクセスを制御する必要があるということ。このアクセス制限、今回は time.sleep() で対応しました。 60秒 ÷ 10 = 6、 6秒に 1回アクセスしても大丈夫、ということですが安全を考慮して 7秒に 1回のアクセスとしました。
time.sleep(7)
この time.sleep(7) を CSV書き込みの後に設けて処理を実行すると、少し時間はかかりますが自動で各月、各言語の新規リポジトリ数を Python が CSV に保存してくれます。
そして最後に CSVファイルのダウンロードを実行すれば、自分のパソコンに作成した CSV ファイルを保存。
あとは CSV ファイルなのでエクセルや Googleシートなどで傾向を確認したり、グラフ化したりするとデータ分析できるでしょう。
今回は 3つの言語と 2年間月別データでしたが、 Python の配列構造を変更すると 10言語でも 20言語でも大丈夫ですし、 API URL を変更すれば フレームワーク別 など好きなデータを取得することができます。そしてさらに今自分で設定した API の URL を GET、 POST 式で管理できると Webアプリケーションに。グラフ機能なども混ぜると本格的なアプリになりそうですね。
【本稿でご紹介した GitHub の API からリポジトリ数を取得、保存するコード】
【本稿のプログラムを実行する様子の動画】
\Webサイト担当者としてのスキルが身に付く/
まとめ
GitHub の API でデータを取得する流れ、参考になりましたでしょうか?上記のようにデータの取得に成功したプログラムも参考になると思いますが、失敗したプログラムもチョット参考になると思います。
- 失敗したプログラム/ リポジトリ数を Webスクレイピングで取得しようとした結果❌
失敗理由は、アクセス制限です。 API の URL(api.github.com) に対してもアクセス制限があるように、 普通の URL(github.com) に対してもアクセス制限があります。特に本家 URL の方は厳しめで、 1分間に 1回のアクセスでも BAN されます。 Webスクレイピングでデータは取得できましたが、アクセス制限でひっかかった、という失敗事例になります。
ご興味ある方は、以下のコードをローカルマシンで実行してみて下さい。 botが起動するので Webスクレイピング初心者の方にとってはおもしろいと思いますよ。

-
失敗のスクレイピング・コード
import datetime import csv import time from selenium import webdriver from selenium.webdriver.chrome.options import Options from bs4 import BeautifulSoup driver = webdriver.Firefox() driver.implicitly_wait(10) language = ["Dart","Kotlin","Java"] """ https://github.com/search?utf8=%E2%9C%93&q=created%3A2018-01-01+language%3AKotlin&type=Repositories&ref=advsearch&l=Kotlin&l=""" """sample_url = "https://github.com/search?utf8=%E2%9C%93&q=created%3A" + date + "+language%3A" + language +"&type=Repositories&ref=advsearch&l=" + language +"&l="""" r = 0 i = 0 for l in language: language_n = language[r] print(language_n) #str today = datetime.date.today() # 今日の日付 search_start_day = datetime.date(2018,1,1) # 検索開始日 next_day_old = search_start_day + datetime.timedelta(days=i) # 初期設定 while today > next_day_old: with open("error.csv", "a") as csvFile: fieldnames = ["Language", "date", "count"] writer = csv.DictWriter(csvFile, fieldnames=fieldnames) next_day_old = search_start_day + datetime.timedelta(days=i) #start day 2018-01-01 data-type datetime print(next_day_old) day_data = str(next_day_old) # data-type String """スクレイピング""" url = " https://github.com/search?q=created%3A" + day_data + "+language%3A" + language_n + "&type=Repositories" driver.get(url) html = driver.page_source.encode('utf-8') soup = BeautifulSoup(html, "html.parser") div = soup.find("div", {"class":"d-flex flex-column flex-md-row flex-justify-between border-bottom pb-3 position-relative"}) result = div.findChildren("h3") result = result[0] result = str(result) x = result[5:11] #repository count language_n = [language_n] # data-type List day_data = [day_data] # data-type List x = [x] # data-type List writer.writerow({"Language":language_n, "date":day_data, "count":x}) csvFile.close() i = i + 1 # 次の日へ language_n = language_n[0] #time.sleep(1) print(str(i) + "回目終わり") time.sleep(7) r = r + 1はじめの内はリポジトリ数をゲットできていますが、10回目付近でアクセスエラーに。結局は github.com ではなく api.github.com にアクセスする必要が。
JSONデータに比べてスクレイピングの方は、データ型の変換を頻繁に行う必要がありました。その分コード量も増えるので、わかりにくくなります。JSONデータ、馴染みのない方が多いと思いますが、少しずつ慣れておくと作業時間の短縮やデータ活用に役立つと思います。
【エラー文】
Whoa there!
You have triggered an abuse detection mechanism.
Please wait a few minutes before you try again;
in some cases this may take up to an hour.
恐らく 66件のデータを短絡的に取得するだけであれば自分で Webページにアクセスし、データをエクセルに保存すれば OK ですが、たぶんそれは Windows 2000 ぐらいまで、時代は違います。劇的に進化する情報産業を味方に付けるには "スピード" が大事です。自分 1人の作業時間で考えれば 66件のデータ取得 30分ぐらいかもしれませんが、同じ作業をする人が日本に 100人いたら 3000分です、 50時間です。しかもこの作業ボリュームが 5年続いたとしたら、 50時間 × 5年 = 250時間、 約 10日分の時間コストです。恐らく GitHub のリポジトリ数限定で考えれば 10分の 1 以下に作業時間を短縮できると思いますし、時間がかかる場合は寝る前にプログラムを実行しておけば、あとは Python が自動でデータ収集して CSV ファイルを作ってくれます。こうした行為、日本の活性化、経済力向上に繋がりそうじゃありませんか?
一人一人が気付いた時にできる人が挑戦すれば、一時的には時間がかかるかもしれませんが、長い目で見れば大きな成果。
プログラミングを仕事や副業、 AI 社会への対応、という点で学習されている方も多いと思いますが、こうした社会貢献もプログラマーならではの仕事ではありませんか?
「でも Python 全然わからない...」「プログラミング、本は買ったんだけどな...」という方、プログラミングスクールはどうでしょうか? 「高い」「面倒くさい」「続かないかも...」いろいろネガティブなキーワードが出てくると思いますが、そのキーワード、どこから取ってきましたでしょうか? だれかのブログ、 ニュース、 広告... どれも自分とは関係のない他人の情報ソースではありませんか? 自分で確かめた上で「高い」と思えば「高い」でしょうし、「続かない」と思えば続かないのでしょう。
なによりも「自分」で確かめてみることが大事ではないでしょうか? 「このデータ本当かな?」「このニュース、この YouTube ほんとかな?」 と思った時、自分で調べたりしませんか? プログラミングスクールも同じように自分で確認してみませんか?
もしこれからも "情報" や IT と関わっていく、いずれはプログラミングできたらいいな、と思っているのなら "今" ちょっとはじめてみませんか?
プログラミングスクールの CodeCamp では、随時オンライ形式の無料体験を実施しています。ご興味ある方は 公式ページ をご確認の上、参考にしてみて下さい。
昨今のプログラミング、 AIブームで無料体験枠の空きが少ないケースもあります。ご少々下さい。またお早めにご確認下さい。







- この記事を書いた人
- オシママサラ








