- 更新日: 2019年11月29日
- 公開日: 2019年11月06日
【データサイエンス】PythonのスクレイピングでFacebookページのデータ収集をしてみよう

Google、 YouTube に継ぎ、 世界第3位のアクセス数を誇る Facebook*。 月間アクティブユーザー数は 24億 5000万ユーザー*で、 2019年 6-9月間の広告売上は 約1兆7400億円*。この 3か月間の広告売上は日本のスズキ自動車の売上と同じ規模*、凄いですね。
さてそんな Facebookのページ、どんな内容のデータがあるか気になりますよね。もしくは "このページ" に "このキーワードあるだろうか?" などデータ検索したかった、という経験をお持ちの方もいらっしゃるのでは?
今回は「データ分析」目線で、 Facebook ページのデータを自動収集してみたいと思います。
【データ収集項目】
- 特定のFacebookページの投稿数
- 特定のFacebookページ内のキーワード検索
- 特定のFacebookページ内の記事のシェア合計数
【PythonでFacebookページのデータを自動収集する様子】
【本稿で学べること】
・ Pythonを使ったWebスクレイピング
・ Pythonの while を使ったループ処理
・ Pythonの正規表現を使って、文字列内の特定文字を検出
・ 配列の行と列を入れ替える
・ 読み取ったHTMLコードをファイルに書き込み、保存
【データサイエンス】PythonのスクレイピングでFacebookページのデータ収集をしてみよう
Facebookページのデータ収集方法

Facebook APIのアクセストークンを取得しようとするが、申請が必要とのアナウンス。 Facebook API の使い方は 2018年から大幅に変わっています。
Facebookページに表示されてるデータを収集しようと思うと以下の方法が挙げられます。
- API
- スクレイピング
基本的には API でデータ収集する方がいいのですが、 2018年 4月からプライバシー保護の観点から API が使いにくくなっています。 YouTube で 「Facebook Graph API」 と検索しても Version 3.0 など古いものしか紹介されていません*。そのため Facebook の API を使って、データ収集しようとすると "申請" が必要に(上図参照)。本格的なアプリを作るのなら API 必須と思いますが、短絡的なデータ収集で API 申請するのはチョット面倒。
そこで今回は、 "Webスクレイピング" を使って Facebookページ内のデータを収集してみたいと思います。
【今回の開発環境】
・実行環境/ 自分のパソコン
・スクレイピング・ライブラリ/ Selenium
・使用ブラウザ/ FireFox
・エディタ/ Visual Studio Code
・対象ページ/ CodeCamp社の Facebookページ
Selenium のインストールがまだの方は事前にお済まし下さい。
【Seleniumな理由】
Pythonで Webスクレイピングを実行しようと思いますと 「Beautiful Soup」 や 「Selenium」 が有名。
今回 Selenium を選択した理由としては、スクレイピングの様子がよくわかるからです。
Pythonプログラムを実行すると "ボット" が起動し、自動で Webブラウザを操作してくれる様子は見ていて楽しいものです。
またエラーがあった時も、エラー文以外に画面のどこで動きが止まったかよく分かりますので、プログラムの修正も行いやすい特徴が。
「おもしろい」「エラーハンドリングしやすい」という 2点から Selenium を選択しました。
PythonでFaceBookページにアクセスする流れ

Facebookページを表示するまでの一連の流れ
普段の Facebook ページの操作というと、ログインはほぼ自動で、ログイン後も自分に関連する情報が自動で表示され、通知アイコンなどをタップして処理を進めていると思います。
この一連の操作、実は自分でやるのと Python(ボット)でやるのでは流れが若干異なります。
実際に一つずつステップを踏みながら Facebook ページにアクセスし、スクレイピングできるよう進めていきたいと思います。
【待ち受ける難関】
- Facebookページにアクセスした時のポップアップ表示問題
- Facebookページのポスト内容はHTML的に hidden だった問題
PythonでCodeCampのFaceBookページにアクセス

上図のPythonコード
import time
import os
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Firefox()
driver.implicitly_wait(10)
url = "https://www.facebook.com"
driver.get(url)
今回は CodeCamp 社の Facebook ページの投稿総数と "投稿のシェア数" を確認したいと思います。ワンステップずつスクレイピング・コードを書いていきたいと思います。
まず上記プログラムを実行すると ブラウザ: FireFox が自動で起動し、 Facebook のトップページが自動で起動。通常であれば自動的にログインしたり、メールアドレス等が自動入力されると思いますが、ボットでブラウザを起動する場合は普段とは違う設定で起動。そのため一つずつ丁寧にボットに指示してあげないと目的のページまでたどり着くことはできません。
次は Pythonコードで "ログイン" に挑戦してみましょう。

さて自分でログイン情報を入力するのは何でもないと思いますが、 Python(ボット) にログインしてもらおうと思うと "どこ" に "ナニ" を書けばいいか、明確に指示してあげる必要があります。
まずログインに必要な "メールアドレス" や "パスワード" の入力欄、ボットに伝えるには HTML コードで "どこ" という場所を教えてあげる必要があります。 "メールアドレス" の入力欄の HTML コードを確認すると
<input type="email" class="inputtext login_form_input_box" name="email" id="email" data-testid="royal_email">
となっています。 Selenium で入力場所の特定をする方法は、
- class
- name
- id
- tag
- text ... etc
メールアドレスを入力する欄には、 class も name も id も要素が入っています。どれにしようか迷うところですが、今回は name を選択。理由は、まれに Facebook のトップページが変わり、 class や id が代わることがあるからです。 name は一定して同じでしたので name を選択しました。
パスワードもメールアドレスと同じ理由で name="pass" を選択し、プログラムに使用。
入力後の "login" ボタンは、 submit というタイプで指定されていますので、 入力後は Python に submit を押してもらうように指示します。

上図のPythonコード
import time
import os
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Firefox()
driver.implicitly_wait(10)
url = "https://www.facebook.com"
driver.get(url)
email_elem = driver.find_element_by_name("email")
email_elem.send_keys("メールアドレス")
password_elem = driver.find_element_by_name("pass")
password_elem.send_keys("パスワード")
password_elem.submit()
time.sleep(2)
"メールアドレス" と "パスワード" の入力指示を書いたものが上記コード。プログラムを実行すると Facebook に自動でログインすると思います。尚、上記コードの email_elem.send_keys("") には自分のメールアドレスやパスワードを書いてくださいね。
ログインは自動でできたものの、普段は見かけないようなポップアップが表示されます。このポップアップ、消しておかないとスクレイピングに支障がでますので、 "消す" か "表示させない" ように工夫する必要が出てきます。最初の難関です。

上図のPythonコード
import time
import os
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
options = webdriver.FirefoxOptions()
options.set_preference("dom.push.enabled", False)
driver = webdriver.Firefox(firefox_options=options)
driver.implicitly_wait(10)
url = "https://www.facebook.com"
driver.get(url)
email_elem = driver.find_element_by_name("email")
email_elem.send_keys("メールアドレス")
password_elem = driver.find_element_by_name("pass")
password_elem.send_keys("パスワード")
password_elem.submit()
time.sleep(2)
ボットでブラウザを表示した時に登場する "ポップアップ" 、HTMLのコードは特定しにくいため "消す" という行為はナンセンス。今回は "表示させない" という方法で挑戦。
ブラウザの "ポップアップ" や "JavaScript" の有無は、ブラウザの設定画面もしくは設定コマンドで変更できます。通常 Selenium で ブラウザ: FireFox を起動する時は webdriver.FireFox() ですが、設定を変えたい時は
webdriver.FirefoxOptions()
とオプションモードでブラウザを起動することが可能。そしてポップアップを無効にするよう環境設定を以下のように指示。
options.set_preference("dom.push.enabled", False)
これでポップアップ表示が "無効" モードになりました。実際にプログラムを実行してみると、先程はログイン後に表示されていた "ポップアップ" が表示されません。
次は "CodeCamp" のページを開くようボットに指示を進めていきます。

Facebook の "CodeCamp" のページを開く方法は、以下の 2パターンと思います。
- 検索欄に codecamp と入力し、検索実行
- 最初から codecamp の Facebook ページ URL にアクセスする
今回は、前者の "検索欄に入力" を選択。理由は今までの作業の流れで、ボットを目的の情報収集まで進めるためです。
さて検索欄への入力ですが、先ほどの "ログイン" 同様に HTML コードを確認して、 ボットに指示していきます。上図のように name="q" を利用し、プログラミング。

上図のPythonコード
import time
import os
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
options = webdriver.FirefoxOptions()
options.set_preference("dom.push.enabled", False)
driver = webdriver.Firefox(firefox_options=options)
driver.implicitly_wait(10)
url = "https://www.facebook.com"
driver.get(url)
email_elem = driver.find_element_by_name("email")
email_elem.send_keys("メールアドレス")
password_elem = driver.find_element_by_name("pass")
password_elem.send_keys("パスワード")
password_elem.submit()
time.sleep(2)
input_keyword = driver.find_element_by_name("q")
input_keyword.send_keys("codecamp")
input_keyword.submit()
time.sleep(2)
Facebookトップページの検索欄に "codecamp" と入力し、検索実行を行うと、 codecamp に関連する情報がリストアップされます。この中から CodeCamp のページをクリックしてもらうようにボットに指示。

上図のPythonコード
import time
import os
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
options = webdriver.FirefoxOptions()
options.set_preference("dom.push.enabled", False)
driver = webdriver.Firefox(firefox_options=options)
driver.implicitly_wait(10)
url = "https://www.facebook.com"
driver.get(url)
email_elem = driver.find_element_by_name("email")
email_elem.send_keys("メールアドレス")
password_elem = driver.find_element_by_name("pass")
password_elem.send_keys("パスワード")
password_elem.submit()
time.sleep(2)
input_keyword = driver.find_element_by_name("q")
input_keyword.send_keys("codecamp")
input_keyword.submit()
time.sleep(2)
link = driver.find_element_by_link_text("CodeCamp")
link.click()
time.sleep(2)
リンクのクリックは、 〇〇.click() で実行可能。 〇〇のクリック対象は、 tag や id などありますが、今回はリンクテキストで実行。リンクテキストでピックアップされる部分は、 HTML <a href="">◆◆</a> の ◆◆ 部分になります。
そしてプログラムを実行すると、 CodeCamp の Facebook ページを自動で開くことに成功しました。
Facebookページをスクレイピング

さて CodeCamp の Facebookページを開くことができましたが、過去の投稿内容を確認しようと思うと、スクロールバーを一番下まで移動して、次のページを読み込む必要があります。このようなページデザインのことを "インフィニティ・Webデザイン" といいますが、次のページの読み込み制御は色々です。ページ番号で制御している場合もあれば、 Facebook のように id で制御している場合も(上図参照)。
とりあえず Facebook の場合は、次のページをどういうふうにしたらボット(Python)で読み込めるか悩みますよね。

上図のPythonコード
import time
import os
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
options = webdriver.FirefoxOptions()
options.set_preference("dom.push.enabled", False)
driver = webdriver.Firefox(firefox_options=options)
driver.implicitly_wait(10)
url = "https://www.facebook.com"
driver.get(url)
email_elem = driver.find_element_by_name("email")
email_elem.send_keys("メールアドレス")
password_elem = driver.find_element_by_name("pass")
password_elem.send_keys("パスワード")
password_elem.submit()
time.sleep(2)
input_keyword = driver.find_element_by_name("q")
input_keyword.send_keys("codecamp")
input_keyword.submit()
time.sleep(2)
link = driver.find_element_by_link_text("CodeCamp")
link.click()
time.sleep(2)
page = driver.find_element_by_tag_name("html")
page.send_keys(Keys.END)
今回は Facebookの "次のページ" を、ボットにスクロールダウンしてもらって、次のページを読み込んでもらうように設定しました。
上図のように Selenium のキー操作 Keys.END を実行すると Webページの最下部まで自動でスクロールダウンしてくれます。スクロールダウン以外にも、 Enter キーやバックスペースなどいくつかのタイピング操作をプログラム上でしてもらうことが可能*。
実際に上記プログラムを実行してみると、次のページが読み込まれていることが確認できます。

上図のPythonコード
import time
import os
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
options = webdriver.FirefoxOptions()
options.set_preference("dom.push.enabled", False)
driver = webdriver.Firefox(firefox_options=options)
driver.implicitly_wait(10)
url = "https://www.facebook.com"
driver.get(url)
email_elem = driver.find_element_by_name("email")
email_elem.send_keys("メールアドレス")
password_elem = driver.find_element_by_name("pass")
password_elem.send_keys("パスワード")
password_elem.submit()
time.sleep(2)
input_keyword = driver.find_element_by_name("q")
input_keyword.send_keys("codecamp")
input_keyword.submit()
time.sleep(2)
link = driver.find_element_by_link_text("CodeCamp")
link.click()
time.sleep(2)
page = driver.find_element_by_tag_name("html")
page.send_keys(Keys.END)
i = 1
scroll = 5
while i < scroll:
try:
print("\nループ開始:" + str(i) + "回目")
page = driver.find_element_by_tag_name("html")
page.send_keys(Keys.END)
time.sleep(1.5)
except:
print("error...")
finally:
print("ループOK: " + str(i) + "回目")
i = i + 1
さてページのスクロールダウン、1回だけではすこし前の投稿分しか表示されません。 CodeCamp の Facebook ページ全てを表示させようと思うと繰り替ええし "スクロールダウン" を実行してもらう必要があります。今回は while文 で繰り返しスクロールダウンしてもらうように指示。この時 「何回スクロールダウンすればいいか?」 という問題が発生しますが、 どれだけ投稿数があるか検討もつきませんので、 適当に 100、 150 など指定する必要があると判断しました。とりあえずは ループ が上手く回るかどうかテスト。大丈夫ですね。

ループ文で過去の投稿を確認できるようになりましたので、次は投稿数を数える作業を進めていきます。投稿数を数える方法はいくつかあると思いますが、今回は Selenium を使っていますので、投稿特有の class か tag を拾ってカウントしてみたいと思います。
Facebookの HTML構造は本当に複雑ですが、各投稿を区切っている class に class="_4-u2 _4-u8" が妥当と判断。早速 Selenium の find_elements_by_class_name() で実行してみました。

Facebookページ内の各投稿数をピックアップするために実行した、
find_elements_by_class_name("_4-u2 _4-u8")
なんと該当件数 0。 おかしいですね、ブラウザ上では確認できた HTML class の該当が 0 というのは。試しに 現在ボットが開いている Facebook の HTMLコードを確認してみました。

すると Facebook のページ上では表示されている投稿内容、実は HTMLコードでは無効状態(コメント)になっています(上図参照)。通常 HTML コードでコメントアウト <!-- --> するとブラウザ上にはカッコ内で囲まれた内容は表示されません。内容を非表示にしたい時に使うものですが、 Facebook の場合は投稿内容全てがコード的に "非表示" に。
この HTML 的なことで Selenium のスクレイピングが失敗したと考えられます。

上図のPythonコード
import time
import os
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
options = webdriver.FirefoxOptions()
options.set_preference("dom.push.enabled", False)
driver = webdriver.Firefox(firefox_options=options)
driver.implicitly_wait(10)
url = "https://www.facebook.com"
driver.get(url)
email_elem = driver.find_element_by_name("email")
email_elem.send_keys("メールアドレス")
password_elem = driver.find_element_by_name("pass")
password_elem.send_keys("パスワード")
password_elem.submit()
time.sleep(2)
input_keyword = driver.find_element_by_name("q")
input_keyword.send_keys("codecamp")
input_keyword.submit()
time.sleep(2)
link = driver.find_element_by_link_text("CodeCamp")
link.click()
time.sleep(2)
page = driver.find_element_by_tag_name("html")
page.send_keys(Keys.END)
i = 1
scroll = 2
while i < scroll:
try:
print("\nループ開始:" + str(i) + "回目")
page = driver.find_element_by_tag_name("html")
page.send_keys(Keys.END)
time.sleep(1.5)
except:
print("error...")
finally:
html = driver.page_source
post = html.count("_4-u2 _4-u8")
print(html[0:200])
print("ループOK: " + str(i) + "回目")
print("投稿数:" + str(post))
i = i + 1
Facebookページの投稿内容は Selenium でスクレイピングできないことが分かりましたので、後は HTMLコード を Python の文字列として扱い、必要な情報を抽出していきたいと思います。
まず表示されている Webページの HTMLコードは driver.page_source で取得可能。
html = driver.page_source
で HTMLコードを Python の文字列 html として獲得し、文字列 html 内にいくつ _4-u2 _4-u8 があるか数えることができれば投稿数を把握することができます。文字列内の要素数のカウントには、 関数 count() が便利。プログラムを実行したところ、投稿数を取得することに成功しました。
実際にボットが開いている Webページの要素を確認したところ、 _4-u2 _4-u8 の要素数は 34 と Python プログラムの実行結果と同じことが確認できます(上図右側)。
これで CodeCamp の Facebookページの合計投稿数を確認する準備ができました。今まで控えめにしていたループの回数を増やしてプログラムを実行してみたいと思います。

上図のPythonコード
import time
import os
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
options = webdriver.FirefoxOptions()
options.set_preference("dom.push.enabled", False)
driver = webdriver.Firefox(firefox_options=options)
driver.implicitly_wait(10)
url = "https://www.facebook.com"
driver.get(url)
email_elem = driver.find_element_by_name("email")
email_elem.send_keys("メールアドレス")
password_elem = driver.find_element_by_name("pass")
password_elem.send_keys("パスワード")
password_elem.submit()
time.sleep(2)
input_keyword = driver.find_element_by_name("q")
input_keyword.send_keys("codecamp")
input_keyword.submit()
time.sleep(2)
link = driver.find_element_by_link_text("CodeCamp")
link.click()
time.sleep(2)
page = driver.find_element_by_tag_name("html")
page.send_keys(Keys.END)
i = 1
scroll = 120
while i < scroll:
try:
print("\nループ開始:" + str(i) + "回目")
page = driver.find_element_by_tag_name("html")
page.send_keys(Keys.END)
time.sleep(1.5)
except:
print("error...")
finally:
html = driver.page_source
post = html.count("_4-u2 _4-u8")
print("ループOK: " + str(i) + "回目")
print("投稿数:" + str(post))
file = open("facebook-html-" + str(i) + ".html", "w")
file.write(html)
file.close()
i = i + 1
print("【ループ終了】" )
print("記事数:" + str(post))
とりあえずスクロールダウンのループ回数を 120回にしてプログラムを実行。すると 116回目あたりから投稿数が増えず、一番下までスクロールダウンできている事が確認。投稿合計数 873 となりました。
またスクロールダウンの度にその画面の HTMLコード も保存してみました。

保存した HTMLコードの活用方法は色々あると思いますが、一つは "キーワード検索"。通常 Facebook の検索機能では、各 Facebookページの過去の投稿まで細かく検索してくれません。「この Facebookページに確かこんな投稿あったと思うんだけどな...」といって延々とスクロールダウンした経験があるのは私だけでしょうか?
今回のスクレイピングによって上記のような "検索問題" 解決することができます。例えば CodeCamp が過去に Facebook 上でキャンペーンを行った回数。先ほど自動作成された HTMLファイルをテキストエディタで開き、キーワード検索すれば一発で情報の有無や回数を確認できます。
また Python の find() や in を使っても特定文字が含まれているかどうか瞬時に確認できるでしょう。

あとスクレイピングでできる情報収集としては、 シェアされた記事の数 などでしょう。 Facebook の API を使えれれば細かい情報を入手できますが、 スクレイピングの場合は基本 "文字列" の操作になってデータ収集にも限界が出てきます。
さてシェアされた投稿の合計ですが、この値をピックアップしようと思うと Python 文字列の 正規表現 が役に立ってきます。上図のように シェア2件 という文字の前の HTML コード rel="dialog" に着目します。
「シェア」で文字検索すると、投稿以外のシェアもピックアップされてデータ収集が困難になります。

上図のPythonコード
import time
import os
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import re
options = webdriver.FirefoxOptions()
options.set_preference("dom.push.enabled", False)
driver = webdriver.Firefox(firefox_options=options)
driver.implicitly_wait(10)
url = "https://www.facebook.com"
driver.get(url)
email_elem = driver.find_element_by_name("email")
email_elem.send_keys("メールアドレス")
password_elem = driver.find_element_by_name("pass")
password_elem.send_keys("パスワード")
password_elem.submit()
time.sleep(2)
input_keyword = driver.find_element_by_name("q")
input_keyword.send_keys("codecamp")
input_keyword.submit()
time.sleep(2)
link = driver.find_element_by_link_text("CodeCamp")
link.click()
time.sleep(2)
i = 1
scroll = 2
while i < scroll:
try:
print("\nループ開始:" + str(i) + "回目")
page = driver.find_element_by_tag_name("html")
page.send_keys(Keys.END)
time.sleep(1.5)
except:
print("error...")
finally:
html = driver.page_source
post = html.count("_4-u2 _4-u8")
print("ループOK: " + str(i) + "回目")
print("投稿数:" + str(post))
file = open("facebook-html-" + str(i) + ".html", "w")
file.write(html)
file.close()
i = i + 1
print("【ループ終了】" )
print("記事数:" + str(post))
x = re.findall(r'\brel="dialog">\w+', html)
print(x)
print("シェアのあった投稿数:" + str(len(x)))
投稿のシェア要素をピンポイントでピックアップするために、 シェア1件 というタグ内の情報を抽出します。それには 文字列 の 正規表現 を使えば解決でき、以下のようなコードで シェア○件 を抽出できます。尚、 findall() で文字列内のすべての該当要素をピックアップするように指示しています。
re.findall(r'\brel="dialog">\w+', html)
\b 〇〇 \w+ という決まったパターンで、文字列 rel="dialog"> に続く単語を抽出してくれます。尚、シェア数 0 の投稿については、 HTMLコードが異なりますのでこのプログラムでは抽出されません。
また正規表現を使用する際は import re を忘れないようにしましょう。
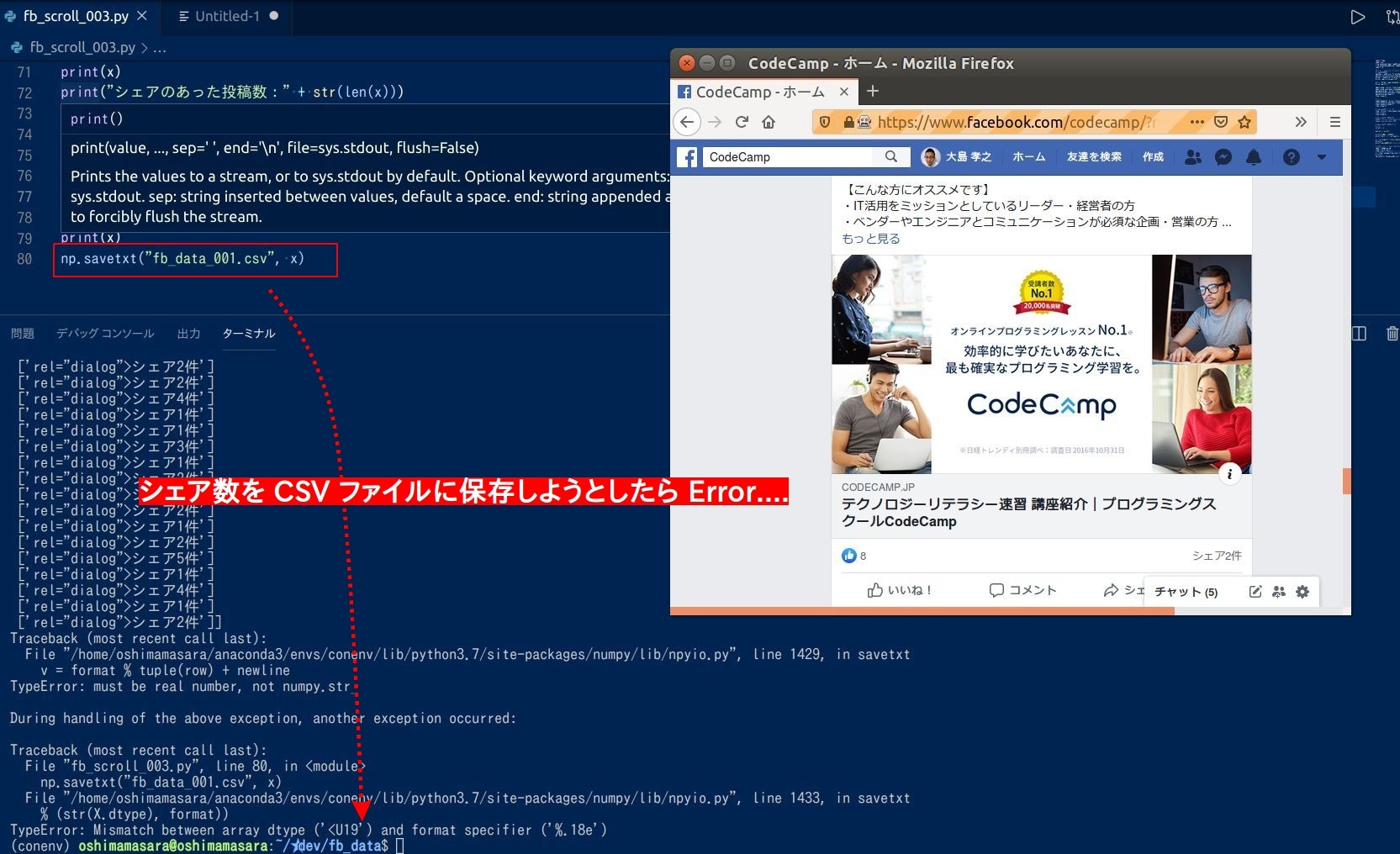
ただシェア数を拾ってくることはできましたが、 1次元の配列にデータが納まっています(上図下の方)。コレでは CSV にシェア数を書き込んでも、一つのセルに情報が入って集計しにくいです。
1次元の配列構造を要素数に応じた行数に変換し、 CSVに書き込んだ後もデータ集計しやすいようにデータ加工します。
上図のPythonコード
import time
import os
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import re
options = webdriver.FirefoxOptions()
options.set_preference("dom.push.enabled", False)
driver = webdriver.Firefox(firefox_options=options)
driver.implicitly_wait(10)
url = "https://www.facebook.com"
driver.get(url)
email_elem = driver.find_element_by_name("email")
email_elem.send_keys("メールアドレス")
password_elem = driver.find_element_by_name("pass")
password_elem.send_keys("パスワード")
password_elem.submit()
time.sleep(2)
input_keyword = driver.find_element_by_name("q")
input_keyword.send_keys("codecamp")
input_keyword.submit()
time.sleep(2)
link = driver.find_element_by_link_text("CodeCamp")
link.click()
time.sleep(2)
i = 1
scroll = 2
while i < scroll:
try:
print("\nループ開始:" + str(i) + "回目")
page = driver.find_element_by_tag_name("html")
page.send_keys(Keys.END)
time.sleep(1.5)
except:
print("error...")
finally:
html = driver.page_source
post = html.count("_4-u2 _4-u8")
print("ループOK: " + str(i) + "回目")
print("投稿数:" + str(post))
file = open("facebook-html-" + str(i) + ".html", "w")
file.write(html)
file.close()
i = i + 1
print("【ループ終了】" )
print("記事数:" + str(post))
x = re.findall(r'\brel="dialog">\w+', html)
print(x)
print("シェアのあった投稿数:" + str(len(x)))
import numpy as np
item = np.array(x)
item_count = len(x)
x = item.reshape(item_count,1)
print(x)
np.savetxt("fb_data_001.csv", x)
配列構造の変更は、 Numpy という Pythonのライブラリを使うと簡単。
item = np.array(x)
item_count = len(x)
x = item.reshape(item_count,1)
print(x)
np.savetxt("fb_data_001.csv", x)
まず シェア数のデータを納めた 変数x を numpy形式に変換(1行目)。そして "シェア数" のデータがいくつあるかを 2行目で確認。その "シェア数" のデータ数分だけの "行" となるように reshape() を実行(3行目)。
これで 一次配列だった "シェアのデータ数" が 2次元配列になって、 CSV にいい感じに書き込めそうになりました。実際に CSV への保存を実行するとエラーが....(上図参照)

上図のPythonコード
import time
import os
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import re
options = webdriver.FirefoxOptions()
options.set_preference("dom.push.enabled", False)
driver = webdriver.Firefox(firefox_options=options)
driver.implicitly_wait(10)
url = "https://www.facebook.com"
driver.get(url)
email_elem = driver.find_element_by_name("email")
email_elem.send_keys("メールアドレス")
password_elem = driver.find_element_by_name("pass")
password_elem.send_keys("パスワード")
password_elem.submit()
time.sleep(2)
input_keyword = driver.find_element_by_name("q")
input_keyword.send_keys("codecamp")
input_keyword.submit()
time.sleep(2)
link = driver.find_element_by_link_text("CodeCamp")
link.click()
time.sleep(2)
i = 1
scroll = 2
while i < scroll:
try:
print("\nループ開始:" + str(i) + "回目")
page = driver.find_element_by_tag_name("html")
page.send_keys(Keys.END)
time.sleep(1.5)
except:
print("error...")
finally:
html = driver.page_source
post = html.count("_4-u2 _4-u8")
print("ループOK: " + str(i) + "回目")
print("投稿数:" + str(post))
file = open("facebook-html-" + str(i) + ".html", "w")
file.write(html)
file.close()
i = i + 1
print("【ループ終了】" )
print("記事数:" + str(post))
x = re.findall(r'\brel="dialog">\w+', html)
print(x)
print("シェアのあった投稿数:" + str(len(x)))
import numpy as np
item = np.array(x)
item_count = len(x)
x = item.reshape(item_count,1)
print(x)
np.savetxt("fb_data_001.csv", x, delimiter = ",", fmt = "%s")
作成した Numpy データの書き込みエラーが起きた原因としては、書き込み時に "データ" のフォーマットを指定していなかったため。 データの区切り delimiter = "," と データ型 fmt = "%s" を指定すると CSV にデータを書き込むことができました。
あとは少しデータ加工するとシェアされた記事の合計数やシェアの合計数など確認することができますね。
CodeCamp提供のPythonデータサイエンスコース
当メディアを運営しているCodeCampではPythonデータサイエンスコースを現役エンジニアのマンツーマンレッスンという形で提供しています。このコースの特徴は
- 数学的な知識がない状態から実務で使えるプログラミングスキルを獲得できる
- 「データ収集」「データ加工」「モデル構築」を習得できる
- 企業のマーケター向けの研修にも取り入れられているカリキュラム
無料レッスン受講後の申し込みで10,000円クーポンをプレゼントしています!ぜひお試しください。
\AIエンジニアに必要なスキルが身に付く/
\AIエンジニアに必要なスキルが身に付く/
まとめ
今回 Python のスクレイピング・テクニックを使って CodeCamp 社の Facebookページをクロールし、情報収集しましたが、「自民党」 と 「民主党」、 「トヨタ」 と 「日産」 など競合する企業団体の情報を収集し、分析をかけてみるのも面白いかもしれませんね。
「こんなデータないかな...」「こんな感じの数字やグラフ欲しいんだけどな...」 営業や経営の仕事をしていれば必ずといっていいほど "情報欲求" が発生すると思います。今回ご紹介したような誰も知らないようなデータ、プレゼンで使えたら人々の興味を引き、交渉や商談をポジティブに導くこと間違いないでしょう。過去 8年間営業していましたので、 "情報" と "交渉" の関係は比例すること、体験済みです。
「しかし、サンプルコードあっても Python の動かし方がよく分からないな...」「シェア数とシェアされた記事の日付知りたいんだけどな...」 なかなか一人では進まないプログラミングも学習環境を変えればスムーズになることも、一度学習環境を見直してみるのはどうでしょうか?
CodeCamp では、 オンライン × マンツーマン で Python や ITリテラシーの向上のレッスンを提供中。 「オンライン・レッスン、馴染みがないのでチョット抵抗あるよな」という方、大丈夫です。 本番さながらの 「無料体験」 で オンラインレッスン がどんなものか体感することができます。
受講料に合うレッスン内容か、 本当にプログラミングができるようになるのか、 ご自身の感覚でテストしてみてください。詳しくは 公式ページ よりチェックしてみてくださいね。
昨今のプログラミング需要の高まりを受けて、無料体験枠が少ない時もあります。お早めにご利用ください。







- この記事を書いた人
- オシママサラ








