- 更新日: 2019年12月26日
- 公開日: 2019年12月21日
【自分でAI開発】8万個のファイルをPythonでデータセット

今回は AI 開発のスタート地点とも言える「データセット」を自分で用意。
データセットの探し方から、データの準備方法までをご紹介。具体的には、アメリカ商務省が公開しているデータセットの中から”大文字のアルファベット”だけをピックアップ。
8万個以上のファイル整理、意外と大変です。
【自分でAI開発】8万個のファイルをPythonでデータセット
データセットの選び方

アメリカ商務省のデータセットのABC
今回は”大文字のアルファベット”をコンピューターにラーニングさせたいと思い、 ”ABC” の画像を検索。結果として以下の様なデータファイルがヒットしました。
- 手書きではない看板文字のアルファベット*(データサイズ 136MB)
- CSVで保存されたアルファベット*(データサイズ 6GB)
- ubyteで保存されたアルファベット*(データサイズ 110MB)
- 消されているTensorFlowのemnistデータセット*
- アメリカ商務省が収集した文字のデータセット*(500MB)
検索方法は、 Googleで「dataset Alphabet」「dataset abc」など。また Google以外に Kaggle という AI開発プラットフォーム内のデータセットを検索。その結果が上記 5つですが、意外と簡単に使えそうなデータセット見つからないな、という印象。
自分でアルファベットの文字画像も作って、ラーニングさせてみましたが、画像枚数が少ないのでなかなか思うような精度はでません。転移学習(MobileNet)も試みましたが、案の定、事前学習内容と”文字”はラーニングの内容が違うため、こちらもいい結果がでない。
また ABCの文字をラーニングさせるのに、使用するデータセットが ”CSV” や "ubyte" 形式だと、ちょっとイメージ湧きにくい...
一つだけ使いやすいと思った”看板の文字”を集めたようなアルファベットの画像データ群、実際にラーニング(MobileNet)させてみましたが ❌。

看板文字 : https://webkid.io/blog/datasets-for-machine-learning/
データセットのアルファベットは”看板スタイル”で、一般的に書く ”文字”とは「形・色」が異なります。色の部分を画像加工できたとしても、文字の形を変えることはできません。結局看板文字は、
認識させたい文字 == ラーニングに使用する文字
でないために、今回のラーニングには適さない画像データと判断。
そして最後に残ったのが、データサイズが大きく、中身がわかりにくいアメリカ商務省のデータ。結果的にこちらのデータセットを使うことにしました。
アメリカ商務省のデータセット
「NIST Special Database 19 Handprinted Forms and Characters 2nd Edition」
2016年にアメリカ商務省が収集した手書きデータで、「数字」「大文字」「小文字」の 3種類のデータ構成。
大文字については、各文字 2000以上あってラーニングに使えそうと判断。
複数のデータファイルが公開されて少しわかりにくいことと、ディレクトリ構造がラーニングに適さないというデメリットが。
パブリックドメインのため、再配布・編集可。
【アルファベットの画像データ】
サイズ: 128 × 128 ピクセル
拡張子: png
枚数: 2000 〜 4400
データセットをPythonで処理するメリット・デメリット

今回利用するデータセットは、 .zip 形式でファイル群が管理されており、解凍(展開)すると各画像を .png で扱うことができます。各画像は様々なフォルダに収納されており、例えば A は、
by_field/hsf_0/upper/41/A.png ・・・・
by_field/hsf_0/upper/41/A.png ・・・・
by_field/hsf_0/upper/41/A.png ・・・・
B は、
by_field/hsf_0/upper/42/B.png ・・・・
by_field/hsf_0/upper/42/B.png ・・・・
by_field/hsf_0/upper/42/B.png ・・・・
といった具合にチョットわかりにくいデータ構造(上図参照)。
ラーニングにデータを使おうと思うと、
DATA/A/A.png ・・・・
DATA/B/B.png ・・・・
とアルファベット毎にデータをまとめる必要が。パソコン上で画像ファイルを操作すれば、 DATA/A 、 DATA/B ・・・各フォルダに各アルファベット画像を ドラッグ&ドロップ すれば完了ですが、今回の画像枚数は 8万オーバー。ちょっとコピペするにはウンザリする量ですよね。
そこで改めてデータファイルを ”パソコンで操作する場合” と ”Pythonで扱う場合” を比較してみました。
| パソコン上でファイル操作 | Pythonでファイル操作 | |
| 操作感 | 簡単 | やや難しい |
| カスタマイズ性 | 低い | 高い |
| 調査力 | 中 | 高い |
| スピード | 低い | 腕次第 |
| 市場価値 | 低い | 高い |
| 必要な知識 | OS操作 | Python |
| 人工知能 | 関係性低い | 関係性高い |
| ワークスペース | OS環境下 | どこでも |
上記表の補足
まずデータファイルの操作感ですが、パソコン上で行う場合は右クリックしてコピペしたり、ドラッグ&ドロップでファイルを移動したり、比較的簡単です。一方、Python上でファイルをコピペしたり、削除しようと思うと os.rename() などコードが必要に。複数のファイルの取り扱いになると for文 も必要になったりしますので、 Pythonの基礎スキルは必須。
カスタマイズ性については、パソコン上では対象のファイルを右クリックして「名前の変更」したり、拡張子を編集したり。画像サイズ等の変更については、一旦画像編集ソフトを起動して操作する必要があります。一方、Pythonの場合は、「右クリック → 名前変更」と単純ではないものの、画像のサイズを変えたり、白黒にしたり、プログラム上でいっぺんにファイルをカスタマイズすることが可能。
「調査力」というのは、例えばフォルダ内の画像サイズを知りたい時、パソコン上でファイルを操作する場合は画像編集ソフトを起動して、サイズ確認となりますが、 Python の場合はプログラム処理で一度にフォルダ内すべての画像サイズを収集することが可能。
「スピード」は、今回の様な 8万枚の画像ファイルを操作する場合を想定。パソコン上で 千とか二千のファイルをいっぺんにコピペしようとしたら、パソコンがフリーズ!?ということも珍しくありませんよね。Pythonで処理すると、こうした”フリーズ”に遭遇しにくいです。
あと「ワークスペース」ですが、パソコン上で 「右クリックとドラッグ&ドロップ」 しかできなかった場合、クラウド環境のマシンではファイル操作、できないですよね。 Python なら OS 機能がないクラウド環境下でも、ファイルを移動したり編集したりできます。 AI や 人工知能、データサイエンスといった最先端の技術に興味ある方は、どこでもファイル操作できた方がいいですよね。
少し長くなりましたが、以上のことを踏まえ、最初は難しい Python のファイル操作ですが、”データセット” というゴールを糧に、頑張っていきましょう。
データセットを作る

今回の目標は、 『ラーニング用のデータを作る』 です。機械学習まで行いませんし、データも .png のまま。 .npy や csv化 などラーニングに落とし込めるレベルまでは行いません。あくまで上図のようなファイルの整理です。
「これだったら Windows 上でやればいいのに、、、」たしかにそれも一つの手段ですが、 Python を使うことで
- フォルダ内のファイルの確認
- 画像ファイルの中身の確認
- 80000枚の画像を RUN ワンクリックで移動
できるようになります。最初はややこしくて難しい点もありますが、Python の基礎の復習やデータ処理、それから今後 10万、 20万とデータが増えた場合でも平気でデータ操作できるという強みが身につきます。
それではワンステップずつ確認しながら、目標である DATA/A、 DATA/B ・・・ までできるようにしていきましょう。実行環境は、 GPUが使える Google Colab を選択しました。
今回のPythonコード(Jupyter Notebook)
今回ご紹介する Jupyter Notebook のコードを見る(.py)
レイアウト上 #記号 表記できないため、コメント文を省略したり、 """ で書いています。ご了承下さい。また GitHub に公開している Jupyter Notebook はコメントも書かれていて、比較的分かりやすいかもしれません。
"""dataset_test_(6_11)_(7)_(2) (10).ipynb
Automatically generated by Colaboratory.
Original file is located at
https://colab.research.google.com/github/oshimamasara/ABC-Handwriting-AI-Checker-App/blob/master/get-dataset.ipynb
"""
""" https://www.nist.gov/srd/nist-special-database-19 """
""" ★NEXT CODE★ """
!curl -LO https://s3.amazonaws.com/nist-srd/SD19/by_field.zip
""" ★NEXT CODE★ """
import zipfile
with zipfile.ZipFile("by_field.zip","r") as zip_ref:
zip_ref.extractall("targetdir")
""" データセット 原型の様子 A について """
""" ★NEXT CODE★ """
import os
dir_number = [0,1,2,3,4,6,7]
total_file_count = 0
for i in dir_number:
A_dir = "/content/targetdir/by_field/hsf_"+ str(i) + "/upper/41/"
file_count = sum([len(files) for r, d, files in os.walk(A_dir)])
print("ディレクトリ:" + A_dir + " Aのファイル数:" + str(file_count))
total_file_count = total_file_count + file_count
print("Aのファイル数合計:" + str(total_file_count))
""" ★NEXT CODE★ """
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
plt.figure(figsize=(20,10))
plt.subplots_adjust(wspace=1)
for i in dir_number:
A = "/content/targetdir/by_field/hsf_"+ str(i) + "/upper/41/41_00000.png"
img = Image.open(A)
npA = np.asarray(img)
plt.subplot(1,8,i+1)
plt.imshow(npA)
""" ★NEXT CODE★ """
""" get image size Numpy Pillow PyGame """
from PIL import Image
from glob import glob
import cv2
sample_images = glob('/content/targetdir/by_field/hsf_0/upper/41/*.png')
for i in sample_images[0:5]:
with Image.open(i) as img:
width, height = img.size
print("ファイル名:" + i + " 幅:" + str(width) + " 高さ:" + str(height))
""" ★NEXT CODE★ """
""" check file type All .png ? """
check_pngs = glob('/content/targetdir/by_field/**/upper/**/*.png')
print(check_pngs[0:100])
print(len(check_pngs))
check_pngs_A = glob('/content/targetdir/by_field/**/upper/41/*.png')
print(len(check_pngs_A))
len(check_pngs_A) == total_file_count
""" ★NEXT CODE★ """
""" How to check .png """
check_png_file = glob('/content/targetdir/by_field/**/upper/**/*.png')
print(".png のファイル形式を確認")
for i in check_png_file[0:5]:
print("ファイル名: " + i)
print(".png? " + i[-4:-1])
print(".pn" in i[-4:-1])
for i in check_png_file[0:5]:
boolean = ".pn" in i[-4:-1]
print("ファイル名: " + i)
if boolean:
print(".png有")
else:
print(".png以外あり")
""" ★NEXT CODE★ """
loop_ok = False
check_png_total = 0
for i in check_png_file:
if loop_ok:
pass
else:
print(".png check Loop Start!")
loop_ok = True
boolean = ".pn" in i[-4:-1]
if boolean:
check_png_total = check_png_total + 1
else:
print("★ .png 以外有り")
print("ファイルチェック対象数: " + str(len(check_png_file)))
print("ファイルチェック数: " + str(check_png_total))
check_png_total == len(check_pngs)
""" ★NEXT CODE★ """
"""全部 .png
次はディレクトリの整理
"""
import shutil
for i in dir_number:
data = "/content/targetdir/by_field/hsf_"+ str(i) + "/upper/" #コピー元
dst="DATA/"+str(i) #コピー先
shutil.copytree(src=data, dst=dst)
!ls DATA/
check_count_files = glob('/content/DATA/**/**/*.png')
print(len(check_count_files))
len(check_count_files) == len(check_pngs)
""" ★NEXT CODE★ """
""" データ移動できたので元データ削除 """
""" Commented out IPython magic to ensure Python compatibility. """
%rm -r sample_data targetdir by_field.zip
!ls
"""#### 次はフォルダ整理(A-Zシンプルに)
現状
A
+ DATA/0/41
+ DATA/1/41
B
+ DATA/0/42
+ DATA/1/42
J
+ DATA/0/4a
+ DATA/1/4a
A
+ DATA/A にまとめる
+ DATA/B にまとめる
作戦
現状の DATA/△/〇〇 内にある .png を DATA/A に移動。
2重Loop
```
for first_dir in △:
for second_dir in 〇〇:
DATA/A に .png をコピペ
```
ところで DATA/△/〇〇 の 丸々は
"""
""" ★NEXT CODE★ """
first_dir = glob("DATA/*")
print(first_dir)
for first_loop in first_dir:
second_dir = glob(first_loop + "/*/")
print(second_dir)
"""取得するディレクトリ情報、並び順はバラバラ
ABC 順番コピーするようにディレクトリを順番通りに読み込む必要が...
"""
""" ★NEXT CODE★ """
first_dir = glob("DATA/*")
first_dir = sorted(first_dir)
print(first_dir)
for first_loop in first_dir:
second_dir = glob(first_loop + "/*/")
second_dir = sorted(second_dir)
print(second_dir)
""" ★NEXT CODE★ """
"""準備OK コピペ開始
貼り付け先の A-Z ディレクトリ作成
"""
print(chr(ord("A")))
print(chr(ord("A") + 1))
""" ★NEXT CODE★ """
new_dir_list = []
print(new_dir_list)
new_dir_list_name = 'A'
for i in range(0, 26):
new_dir_list.append(new_dir_list_name)
new_dir_list_name = chr(ord(new_dir_list_name) + 1)
print(new_dir_list)
""" ★NEXT CODE★ """
for d in new_dir_list:
os.mkdir("DATA/" + d)
""" ★NEXT CODE★ """
"""貼り付け先の A-Z ディレクトリ完成した
次は A-Z に .png をコピペ
と、その前に DATA/0/41/以下 と DATA/1/41/以下 ファイル名一緒
+ DATA/0/41/以下 は、内容 A
+ DATA/1/41/以下 も 内容 A
+ DATA/2/41/以下 も 内容 A
つまりファイルが DATA/A で重複し、実際のデータ数より少なくなる
今回は事前にファイル名を「名前変更」して処理
"""
""" ★NEXT CODE★ """
""" ReName """
i = 0
dir_number = sorted(dir_number)
for loop1 in dir_number:
first_dir = glob("DATA/" + str(loop1) + "/*/")
first_dir = sorted(first_dir)
for loop2 in first_dir:
copy_files = glob(str(loop2) + '*.png')
for s in copy_files:
print(s)
renames = s[:-4]
renames = renames + "_" + str(i) + ".png"
print(renames)
os.rename(s, renames)
print(s)
i = i+1
"""全 .png ファイル名がオリジナルなものになったので、 A は DATA/A 、 B は DATA/B に集約"""
""" ★NEXT CODE★ """
p = 0
m = 0
n = 0
loop1_times = 0
dir_number = sorted(dir_number)
for loop1 in dir_number:
print("**********************************************************")
first_dir = glob("DATA/" + str(loop1) + "/*/")
first_dir = sorted(first_dir)
loop1_times = loop1_times + 1
print("回数" + str(loop1_times))
print(first_dir)
for loop2 in first_dir:
print("---------------------------------------------------------------")
loop2_times = n+1
copy_files = glob(str(loop2) + '*.png')
print("コピペするファイル数: " + str(len(copy_files)))
p = p + len(copy_files)
paste = "DATA/" + new_dir_list[n]
for s in copy_files:
loop3_times = m
print("★★ " + str(loop1_times) + "-" + str(loop2_times) + "-" + str(loop3_times))
print("保存先:" + paste )
shutil.copy2( s , paste)
print(s)
m = m + 1
print("copy_files OK\n")
n = n + 1
print("★★for文: loop2 終了★★")
n = 0
print("コピペしたファイル数: " + str(p))
print("コピペした回数: " + str(m))
int(p)==len(check_pngs)
m==p==len(check_pngs)
"""うまくいった?
A-Z のファイル数を改めて確認
"""
""" ★NEXT CODE★ """
oktotal_file_count = 0
for i in new_dir_list:
ok_dir = "DATA/" + i +"/"
print(i)
file_count = sum([len(files) for r, d, files in os.walk(ok_dir)])
print("ディレクトリ:" + ok_dir + " ファイル数:" + str(file_count))
oktotal_file_count = oktotal_file_count + file_count
print("DATA内の合計ファイル数:" + str(oktotal_file_count))
"""DATA/A DATA/B に編集できたので、いらなくなった DATA/0 DATA/1 を消す
そして DATA フォルダを圧縮(zip)して、データセットとして使えるように
"""
""" ★NEXT CODE★ """
for r in dir_number:
shutil.rmtree("DATA/"+str(r))
shutil.make_archive('ABC_data', 'zip', root_dir='DATA')
""" ★NEXT CODE★ """
!rm -r DATA
PythonでZIPファイルのダウンロード

まず今回使用するアメリカ商務省のデータをダウンロード。

ダウンロードサイズは 515MB あるので、 1分ほど時間がかかります。ダウンロード完了すると左サイドバー内に .zip が登場。
PytthonでZIPファイルを解凍(展開)

そしてダウンロードした .zip ファイルを解凍(展開)。フォルダを辿って大文字が保存されている upper フォルダを開くと画像が確認できます。ラーニングには良さそうな画像データですね。
解凍したフォルダの画像データ数を確認(Aのみ)

次はラーニングに使用する ”A” 画像がどれぐらいあるか調査。 A は、 hsf_0 〜 hsf_7 の upper/41 という 41 フォルダに入っています。その 41 フォルダ内のファイル数を数えると A 画像の数を算出できます。今回使用する A 画像は、 3033枚あることが確認できます。いい感じですね。
画像データファイルをPythonで表示
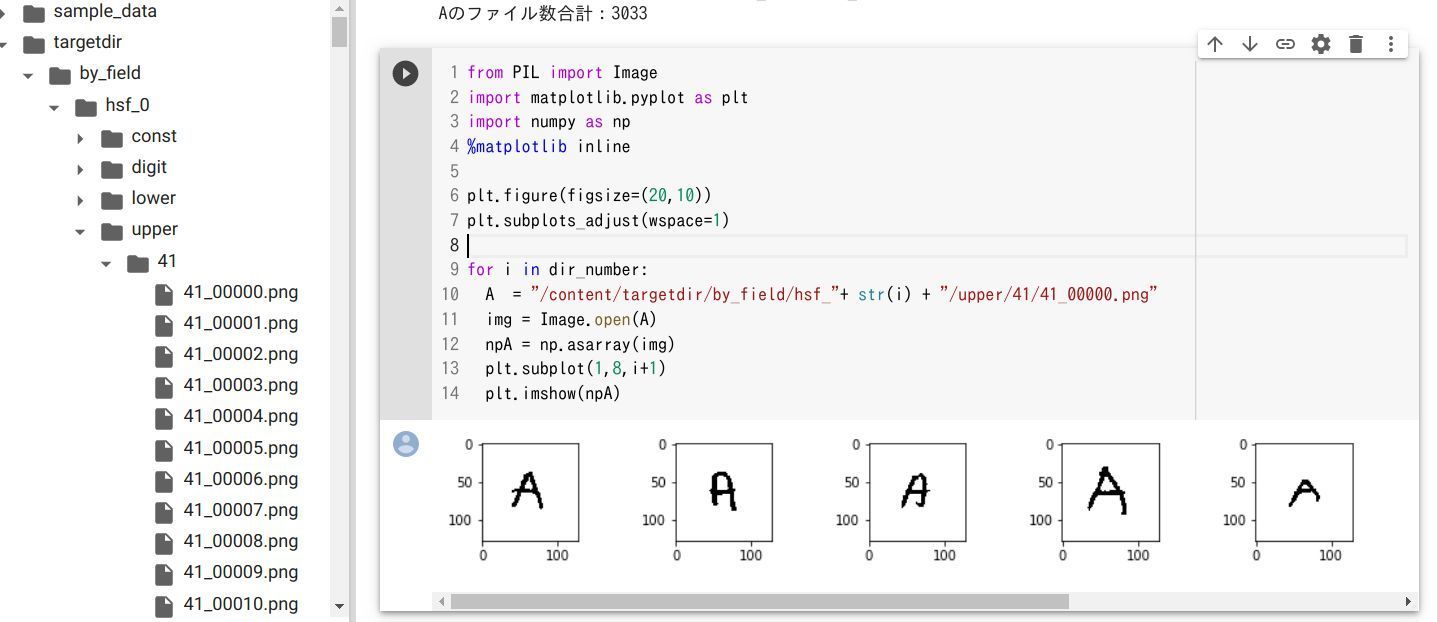
次は各 A画像の確認。左サイドバーの .png ファイルをダブルクリックすればファイル開いて画像確認できますが、あえてPythonで画像ファイルをOPENしてみます。 Colab 以外の Kaggle などで Jupyter Notebook 使用する時には、Python で画像をチェックする必要があるのでこうしたテクニックも知っておきたいですね。
画像ファイル内の画像サイズをPythonで確認

Python の matplotlib で画像を開くとなんとなく画像サイズも分かりますが、数値的に確認しておきましょう。 Pillow ライブラリを使うと画像サイズ確認できます。
フォルダ内の画像ファイルは全部PNGかどうかチェック

今回取り扱うファイル数は 8万、プログラムをテスト&実行する時は、マシン負荷と処理時間を考慮して、サンプリングを行いながら進めていくのがベスト。まずは .png の拡張子を判定できるプログラムを上記の様に作ってテストラン。各ファイルが .png であるかどうか、判断できそうですね。

次はもし .png 以外の拡張子があった場合の処理を指示。プログラムで取得できる .png の .pn をキーにして、 .pn があるかどうかを真偽値でチェック。 上記コード 4行目の if boolean: は、 if boolean = True と同じ意味で、今回の場合はファイル名の末尾に .pn があれば True、なければ False という処理に。テストではどのファイルにも .pn があるので True の処理に。

8万の全ファイル、 .png であるかどうかチェックする前に、プログラムがきちんと全ファイルをチェックするかどうか”カウンター”機能を付けることも重要。今回は、 check_png_total という変数を使って、ファイルチェック数を確認。プログラムを実行すると、 81463全ファイルをチェックしたことが確認できます。
ちなみに for文直後の if文は、 forループが始まった時、一番最初だけ文字を出力したい時のプログラムになります。
【forループ 一番最初だけ文字出力】
if loop_ok:
pass
else:
print(".png check Loop Start!")
loop_ok = True
ファイルの移動

ターゲットの大文字アルファベットファイルを操作しやすいようにファイル移動
今回取り扱う大文字のアルファベット・データ数、ファイル形式を確認できたら、次はファイルを /targetdir/by_field/hsf_0/upper/41/41_00000.png から /DATA/0/41/41_00000.png など扱いやすいように移動。一度に元の場所から DATA/A/41_00000.png に移動する方法もありますが、順を追って進めていく方がわかりやすいと思います。

ファイルのコピペには便利なメソッド: shutil.copytree() を使用します。上図のように ”コピー元” と ”コピー先” ディレクトリを決めて shutil.copytree() を実行すれば、ディレクトリ内のファイルが一度に移動。
ファイルコピペ後のファイル数確認

きちんとファイルが移動できたかどうか上記のようなコードで確認できます。 .png ファイル数を glob() メソッドで収集し、確認していますね。
元のファイルとフォルダを削除

元のフォルダやファイルは不要になりますので一旦削除します。こちらは Python ではなく、コマンドで手っ取り早く処理。 Jupyter Notebook では、 ! や %を使うことで、コマンド操作もできます。 rm 以外にも pip install や python -V など。
フォルダ整理の準備(ディレクトリ構造を確認)

Colab画面左のフォルダを見れば分かることですが、あえて Python で現在のディレクトリ構造を確認。 DATA/1/4b の中に K 画像、 DATA/6/4b の中にも K 画像。幸いどのアルファベットも A なら 〇〇/△/41 ディレクトリ、 B なら 〇〇/△/42 ディレクトリと画像ファイルの親フォルダは同じ名称。
つまり A 画像を DATA/A に集約したい場合は、以下のようなファイル移動。

DATA/0 の 41ディレクトリ、 DATA/1 の 41 ディレクトリ、と 41ディレクトリをクロールして A画像ファイルを DATA/A に送り込めばよさそうですね。
ディレクトリをいくつかまたいで処理していきますので、チョットややこしくなりますが、一つずつ進めれば大丈夫でしょう。
ところでサブディレクトリを表示させた上記 Python コード結果、ちょっと見難いですよね。出力結果を順序よく並べようと思うと sorted() が便利です。

画像ファイルの貼り付け先準備

Python でファイルをコピペする場合、事前に貼り付け先のディレクトリを用意しないといけない場合とそうでない場合があります。今回のコピペ処理、まだどのメソッドで実行するか決めていませんが、とりあえず貼り付け先の DATA/A 、 DATA/B ・・・ を用意。
一つずつ名前を決めて os.mkdir() を実行する方法もありますが、できればプログラミング的にカッコよく処理したいもの。 for文を使えばよさそうですが、 A とか B 、数字みたいに繰り返し処理できるでしょうか?
Python では文字や記号を管理するメソッド chr() があります。例えば chr(100) とすれば d が返ってきますし、 chr(10000) とすれば ✐ マークが返ってきます。この chr() を使えば文字も数値的に管理できるというもの。
上図では chr(ord("A")+1) で A の次の B を出力していますね。順番に +1 してもらい、 Z までループと決めておけば A-Z の文字配列を取得できます(上図2番目のプログラム)。
そして A-Z の文字を os.mkdir() で順番に処理していけば、いちいち ”フォルダを作成” を繰り返さなくてよくなります(上図3番目のプログラム)。
貼り付けファイルの確認

貼り付け先のフォルダが準備出来たので、さあコピペ、としたいところですが、このままコピペすると正しくファイルをコピペできません。理由は、貼り付け元の画像ファイル、同じ名称だからです(上図参照)。

コピペ元のファイルを確認すると、画像は違うのに同じファイル名のモノが。
パソコン上でファイルをコピペする場合、ファイル名が重複したら 〇〇(1).png など 自動的に () が加えられて、ファイルの上書きを防ぎます。 Pythonのコピペでこのようなファイル処理をしようと思うと、 if文でファイル名をチェックし、それからファイルのコピペ処理という流れに。 if文でチェックしなかった場合は、ファイルはどんどん上書きされて、本来用意していた画像データよりファイル数が少なくなるという結果になりかねません。
if文で上書きを回避するか、もしくは元データのファイル名を変えて、全て独自のファイル名に変更するという手段もあるでしょう。
今回は、コピペのプログラムがちょっと複雑になりますので、ファイル名の変更処理を前もって行うことにしました。
8万個のファイルを一気に名前変更

今回はファイル名を重複しないようにするため、 DATA/0 、 DATA/1 など DATA 直下のディレクトリ名をファイル末尾に加えることに(上図参照)。他には、 time() で現在時刻を取得し、ファイル名に加えるという方法もあるようです。
そして各ディレクトリ内のファイル名を変更するために for文を使って、フォルダ内をクロール。このように何回も for文を使う方法も一つですし、 walk() というメソッドを使うのも一つでしょう。今回はわかりやすい for文で名前変更に挑戦。

各ディレクトリを for文でクロールし、最終的に .png のファイル群は 配列: copy_files に格納。そして copy_files 内の画像ファイルを s として一つずつ取り出し、 名前変更の処理。名前変更処理は、 os.rename() ではなく、文字列の変更で対処。 モジュール: shutil を使った名称変更方法もありそうですが、シンプルな処理を優先しました。
ファイル名の末尾に加える数字は、 変数: i で管理。 DATA/0 ディレクトリをループしている時は i=0、 そして DATA/1 ディレクトリのループになると i=1 という具合に名称を変更。そのため今回ディレクトリは、 DATA/0, DATA/1, DATA/2, DATA/3, DATA/4, DATA/6, DATA/7 と 5 が抜けていますので、 DATA/6 内のファイル名だけ 〇〇_5.png と 6ディレクトリなのに 5 が使われます。ご了承下さい。

プログラムの実行が終わったら、 Colab 左サイドバーのファイル名をチェックしてみて下さい。全画像ファイル名、変わっていると思います。
8万個の画像ファイルを一気にコピペ

いよいよ最終段階です。アルファベット・ファイルを DATA/A 、 DATA/B に集約していきます。
プログラムを実行すると、 DATA/0 、 DATA/1 と順番にコピー元をプログラムがクロールし、 DATA/A 、 DATA/B など各画像データにあったフォルダへコピペ。さすがに 8万回以上のコピペになりますので、 4、5分時間がかかります。早く済ませたい場合は、 上記プログラムの print()文を無効にすれば早くなります。
さてこちらのコピペ・プログラム、ポイントはファイル群のクロール制御を司る n です。

まず n の初期値は 0、この n=0 によってファイルの貼り付け先は DATA/A に。 上図 21行目の
paste = "DATA/" + new_dir_list[n] # 貼り付け先 A, B, C...
new_dir_list[n] は配列構造で、 A, B, C ・・・ が収納されています。
new_dir_list = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z']
つまり n=0 の時は、 new_dir_list[0] となって最初の値 A が引き当てられることに。その結果、 貼り付け先は DATA/A という結果。
この 23行目のループが終了すると n に 1が足されて、 n=1に。そして 15行目のループに戻ります。なかなかコードではイメージしにくいかもしれませんので、上記の流れを”図”にしてみました。
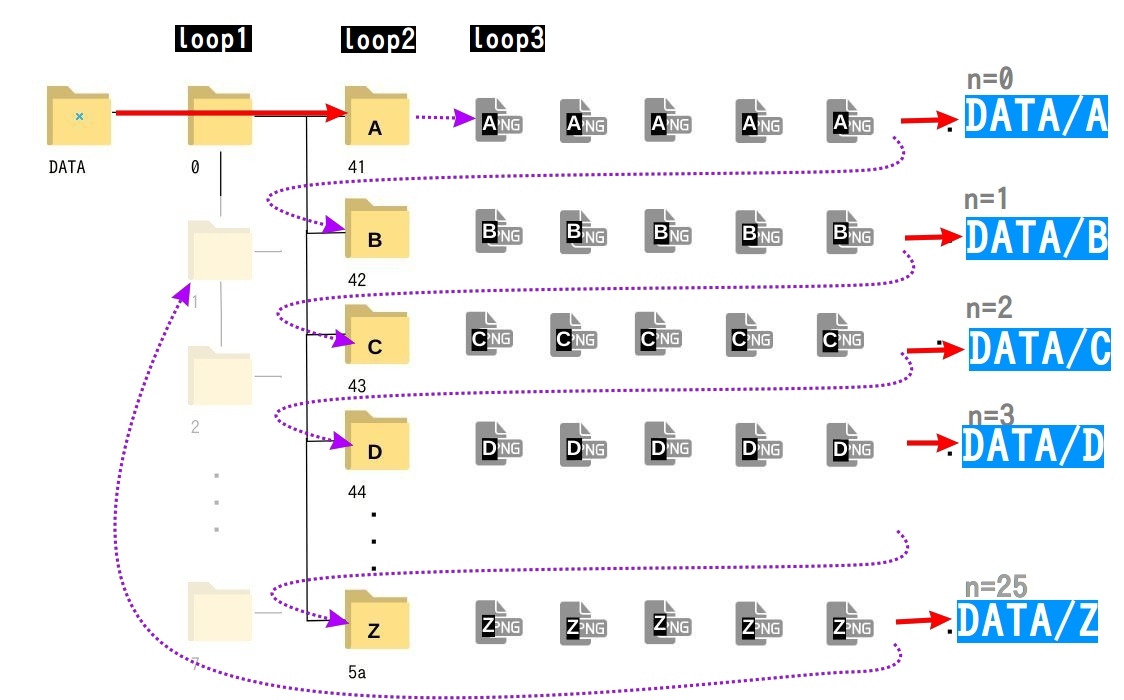
一番最初のループ処理 n=0 の時は、 DATA/0/41 フォルダ内の A画像を DATA/Aフォルダにコピペ、その処理が終わると DATA/0/42 フォルダ内の B 画像を DATA/0/B フォルダにコピペ。これを DATA/0/5aフォルダまで繰り返し行います。
そして DATA/0/5a つまり ”Z” までクロールしたら、次は DATA/1/41 というルートに進みます。

今度は DATA/1 内にあるアルファベットの画像をクロールしてコピペ。先ほどと同じように n=0 で A画像フォルダの 41フォルダ内データを DATA/A にコピペ、 n=1 で B画像フォルダの 42フォルダ内データを DATA/B にコピペ、と繰り返し処理。そして n=25 の ”Z” 画像まで処理できたら DATA/2 フォルダに移動して改めて A の DATA/2/41 フォルダをクロール、と DATA/7 フォルダまで繰り返し処理。
ご紹介しているプログラムでは、コピペ毎に print()文を実行していますので、処理に時間がかかります。手っ取り早くファイルのコピペを終えたい場合は、 print()文を無効にしてプログラムを実行してみて下さい。
ファイルのコピペ、今回は 1ファイルずつ指定のフォルダにコピペしていく処理にしましたが、フォルダ内のデータを新しいフォルダにコピペ、という方法もあります。
フォルダ内のデータをフォルダに移すモジュール: shutil.copytree()
shutil.copytree()の利用も検討しましたが、複数のフォルダをクロールする一方で、貼り付け先は DATA/A DATA/B とコピーするフォルダ数とペーストするフォルダ数が違う関係に。
・コピーするフォルダ数 182 ・ペーストするフォルダ数 26
すると shutil.copytree() を実行すると、データを含む既存フォルダにはペーストできないというエラーに。何か改善策あったかもしれませんが、ファイル一つずつコピペする方が分かりやすいと思い、今回は copy2() というメソッドでコピペしていきました。
8万個のファイルが正しくコピペできたか確認

コピペが正しく実行されたかどうか、まずは貼り付け先の DATA/A DATA/B ・・・ のファイル数を確認してみましょう。そして DATA/A DATA/B ・・・ のファイル数を合計すると 81463 で、最初の方に .png の総数を出した check_png_file と同じ値、元データを新しいフォルダにコピペできたことが確認できます。
画像データ自体も正しくペーストされているかどうかは、画像ファイルを開いて確認してみて下さい。元画像と同じようにローマ字が表示されると思います。
新しいデータセットを圧縮

.zip がいいか .tar.gz がいいか、圧縮方式はさておき、アルファベットデータが集約された DATA フォルダを管理しやすいように圧縮。あとは ZIPフォルダをダウンロードしたり、 GitHub に push したりして保管すれば OK。
\AIエンジニアに必要なスキルが身に付く/
まとめ
今回は AI のアプリ開発を行うために必要なデータセットを準備したわけですが、 Python の基本的なプログラムが多数登場し、Python初学者にとっては”いい”復習になったのではないでしょうか?
尚、こうしたデータセットの作り方は Web 上で見当たらず、自分で考えて”元データ”から”目標”に導く必要が。ファイルをコピペする方法が、 shutil.copyfile()、 shutil.copy()、 shutil.copy2()、 shutil.move()、 shutil.copytree() とたくさんあるように、このやり方が一番正しい、というのはなく、元データと目標からプログラムを考える必要がありますね。
「Python、独学しているけど、コレでいのかな?」「人工知能の本買ったけど...」と学習に不安を覚えたり、学習が進まない方、プログラミング・スクールの検討は ”済” でしょうか? もしまだ ”無料体験” をされていなかったり、”無料相談” も行っていない場合は、どうでしょう、一度プログラミング・スクールの世界、覗いてみませんか?
受講費用、というコストはかかりますが、これからの将来を考えると必要な、適切な ”自己投資” かもしれません。学習が止まっている時間、実はその時間 ”ロス” かもしれませんね。
オンラインのマンツーマン・レッスンで定評のある CodeCamp では、無料体験時に簡単なプログラムも動かしてレッスン環境を体験。東証一部上場企業のグループ会社なので、”無料体験”後の 営業 も控えめ。日常生活に支障をきたすことなく、安心して検討できます。
自分の将来を本気で考えるなら、プログラミングスクール、検討してみませんか?
無料体験の情報、申し込は 公式ページ より確認してみて下さい。





![[Python初心者向け]Flaskの使い方](https://mash-jp.cdn.codecamp.jp/production/posts/34801/20db6f432333c5b889abaa6febb8741be1c3213a.34846.phone.jpeg?1576744015)

- この記事を書いた人
- オシママサラ








