- 公開日: 2020年01月31日
【SEO&WEB担当者必見!】Mixed Content(混合コンテンツ)対策-1267ページ分

2019年10月に公開された一本の Blog。
2020年 2月のバージョンアップで <img> タグの URL が http:// だった場合、 https:// に自動変更し、アクセスする
Google Online Security Blog: No More Mixed Messages About HTTPS
いわゆる Mixed Content 対策ですが、 皆様お済みでしょうか?
まさかプラグインで サクッ と... なんて考えておられませんか?
今回は Mixed Content とその対策についてレポートさせて頂きます。
Mixed Content(混合コンテンツ)に対する対応は、ブラウザによって違います。
今回はブラウザシェア No.1(約 70%) の Google Chrome を主体に解説します。
ブラウザ = Google Chrome
【今回の混合コンテンツ対策対象サイト】
https://blog.codecamp.jp
内容を理解すれば、他サイトでも実行可能と思います。
【SEO&WEB担当者必見】Mixed Content(混合コンテンツ)対策-1267ページ分
Mixed Content(混合コンテンツ)とは

ドメイン自体は https 化されてるけれども、サイト内に http:// のリンクが含まれる Webページを 「Mixed Content(混合コンテンツ)」 といいます。
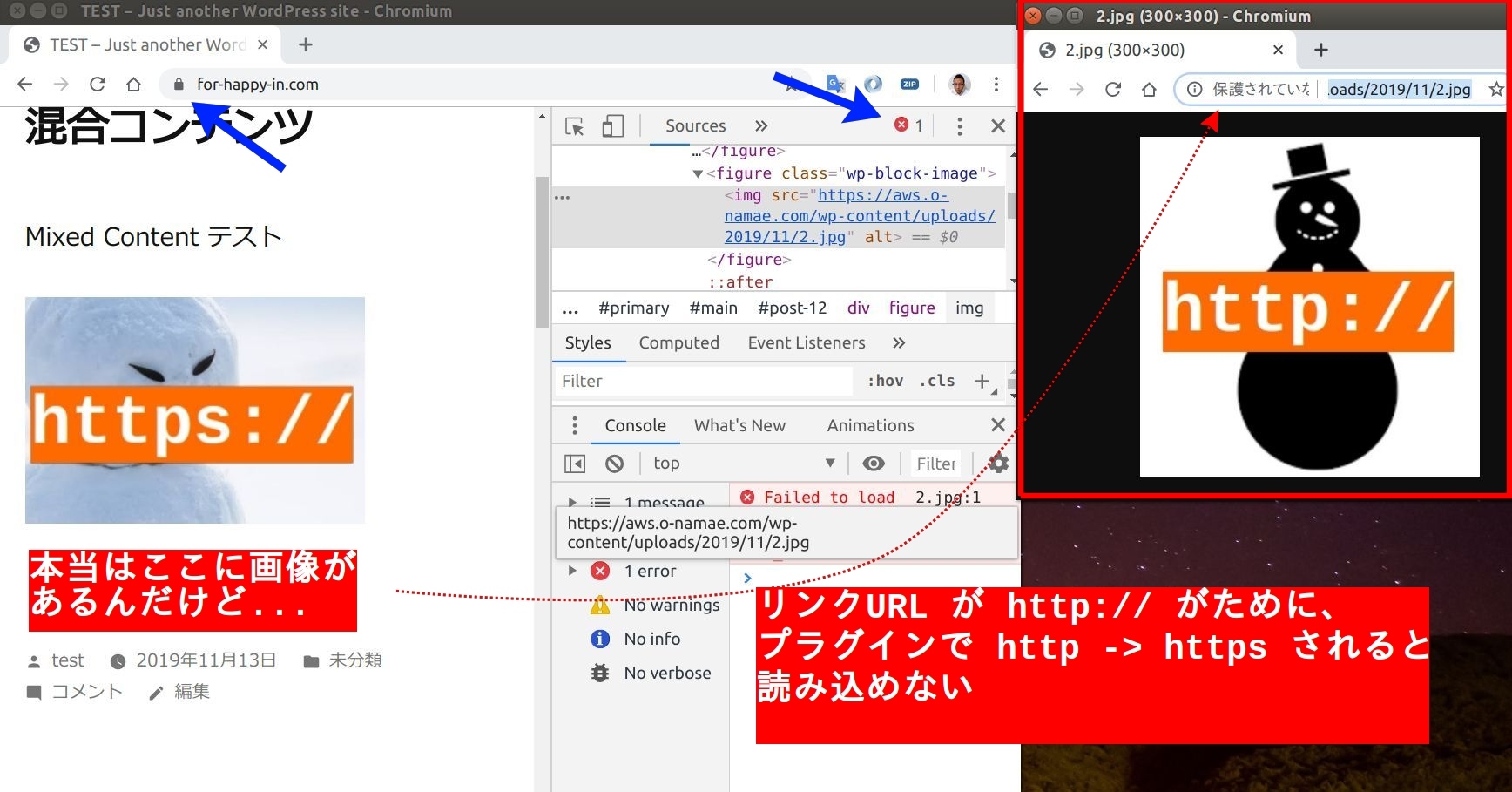
2018年ぐらいまでは静的なサイトであれば http:// でもブラウザは特に警告を出してきませんでしたが、 最近は http:// であれば何でも "セキュアじゃない" マークを表示するようになりました(下記画像参照)。

ブラウザ:FireFoxの例 http://aws.o-namae.com
こうした流れを受けて多くの方は運営サイトを https:// 化 されたと思いますが、 サイト内のリンクまではチェックしていませんよね。内部リンクについてはドメインが https:// になったので大丈夫と思いますが、外部リンクは 「https:// の URL」 と 「http:// の URL」 まぜまぜと思います。
中には "画像" や "動画" コンテンツを外部サイトから引用して、 <img src="http://〇〇.com"> でサイト内に画像を表示しているケースも少なくないでしょう。このケース、実は 2020年 2月までに対策しておかないとヤバイ・・・かもしれません。
Mixed Content(混合コンテンツ)ブラウザの変更スケジュール

上図左 2019.11 版の HTMLコードを今見る
<!DOCTYPE html>
<html lang="ja"><head>
<meta charset="UTF-8">
<title>Mixed Content Test</title>
</head>
<body>
<h1>Mixed Content Test Page</h1>
<h3>2019.11 ミックスコンテンツ警告表示のみ</h3>
<h3>http:// -> https:// 自動変換なし</h3>
<table style="text-align:center" width="100%">
<tbody><tr>
<td style="vertical-align: top;background-color: antiquewhite;" width="50%">
<h2>リンク</h2>
<ul>
<li><a href="http-2.html">http-2.html</a></li>
<li><a href="http://appleplugs.com/">http://appleplugs.com</a></li>
<li><a href="https://blog.codecamp.jp">https://blog.codecamp.jp</a></li>
<li><a href="http://goinc.co.jp/">http://goinc.co.jp</a></li>
</ul>
</td>
<td style="vertical-align: top;background-color: #ecffe3;" width="50%">
<h2>画像</h2>
<br>
<img src="1.jpg" height="200px">
<img src="http://aws.o-namae.com/wp-content/uploads/2019/11/2.jpg" height="200px">
</td>
</tr>
<tr>
<td style="vertical-align: top;background-color: #ecfdfb;">
<h2>オーディオ</h2>
<br>
<p>https://</p>
<audio controls="">
<source src="horse.mp3" type="audio/mpeg">
</audio>
<br>
<p>http://</p>
<audio controls="">
<source src="http://aws.o-namae.com/wp-content/uploads/2019/11/horse.mp3" type="audio/mpeg">
</audio>
</td>
<td style="vertical-align: top;background-color: #faeeed;">
<h2>ビデオ</h2>
<video controls="" width="200">
<source src="video-https.mp4" type="video/mp4">
</video>
<video controls="" width="200">
<source src="http://aws.o-namae.com/wp-content/uploads/2019/11/video-http.mp4" type="video/mp4">
</video>
<div></div></td>
</tr>
</tbody></table>
</body></html>
上図右 2020.02 版の HTMLコードを今見る
<!DOCTYPE html>
<html lang="ja"><head>
<meta charset="UTF-8">
<title>Mixed Content Test</title>
</head>
<body>
<h1>Mixed Content Test Page</h1>
<h3>2020.02 IMG、 VIDEO、 AUDIO 自動変換</h3>
<h3>http:// -> https:// 【対象: <img>、 <video>、 <audio>】</h3>
<table style="text-align:center" width="100%">
<tbody><tr>
<td style="vertical-align: top;background-color: antiquewhite;" width="50%">
<h2>リンク</h2>
<ul>
<li><a href="http-2.html">http-2.html</a></li>
<li><a href="http://appleplugs.com/">http://appleplugs.com</a></li>
<li><a href="https://blog.codecamp.jp">https://blog.codecamp.jp</a></li>
<li><a href="http://goinc.co.jp/">http://goinc.co.jp</a></li>
</ul>
</td>
<td style="vertical-align: top;background-color: #ecffe3;" width="50%">
<h2>画像</h2>
<br>
<img src="1.jpg" height="200px">
<img src="https://aws.o-namae.com/wp-content/uploads/2019/11/2.jpg" height="200px">
</td>
</tr>
<tr>
<td style="vertical-align: top;background-color: #ecfdfb;">
<h2>オーディオ</h2>
<br>
<p>https://</p>
<audio controls="">
<source src="horse.mp3" type="audio/mpeg">
</audio>
<br>
<p>http://</p>
<audio controls="">
<source src="https://aws.o-namae.com/wp-content/uploads/2019/11/horse.mp3" type="audio/mpeg">
</audio>
</td>
<td style="vertical-align: top;background-color: #faeeed;">
<h2>ビデオ</h2>
<video controls="" width="200">
<source src="video-https.mp4" type="video/mp4">
</video>
<video controls="" width="200">
<source src="https://aws.o-namae.com/wp-content/uploads/2019/11/video-http.mp4" type="video/mp4">
</video>
<div></div></td>
</tr>
</tbody></table>
</body></html>
Googleブログによると、適切に対策をしなかった場合、 2020年 2月には上図のように画像が表示されない箇所が出てくるかもしれない、と公表しています。 画像、動画、音声に関するコンテンツが影響予定で、 2020年 2月までに少しずつ変わる予定となっていますので、下記表に変更予定をまとめます。
| バージョン | <a> | <iframe> | <img> | <video> | <audio> | |
| 2019.11 | 78 | 変更なし | http:// ❌ | 変更なし | 変更なし | 変更なし |
| 2019.12 | 79 | 変更なし | http:// ❌ | 変更なし | 変更なし | 変更なし |
| 2020.01 | 80 | 変更なし | http:// ❌ | 変更なし | http:// ❌ | http:// ❌ |
| 2020.02 | 81 | 変更なし | http:// ❌ | http:// ❌ | http:// ❌ | http:// ❌ |
実は <iframe> についてはもう既に http:// だと読み込んでくれないんですね。 Chrome 以外の Safari や FireFox でも http:// の Webページの <iframe> は下記のようにダメですね。

上図 の iframe サンプルの HTMLコードを今見る
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<title>Mixed Content Test(iframe)</title>
</head>
<body>
<h1>Mixed Content Test Page</h1>
<iframe src="http://aws.o-namae.com/" width="300px"></iframe>
</body>
</html>
この状態が運営サイトにあるとすれば Googleウェブマスター もしくは Googleアナリティクス によって "リンクエラー" が出ていると思いますが、これから起きるであろう "リンクエラー" は Gogole のツールを使ってもわからないと思います。
Google はまず 2019年 12月に Chrome のバージョンを 「Chrome 79」 にアップグレードする予定です。これに伴って Mixed Content(混合コンテンツ) を設定で 「許可する」「許可しない」 と選択できるようになる予定。実際に使っていないので詳しくはわかりませんが、 "基本的に http:// のリンクをブロックする方針" と書かれていますので、デフォルトでは 「許可しない」 に設定されていると考えられます。つまり 2019年 12月 に 「Chrome 79」 にアップグレードされると、とりあえずは今と概ね同じような Web表示 となるでしょう。
そして 2020年 1月になると 「Chrome 80」 をリリース予定。こちらでは <iframe> の他に <video> と <audio> も混合コンテンツの場合、基本ブロックする(非表示)と書かれています。言葉ではイメージしにくいので Webページで 2020年 1月の 「Chrome 80」 を再現してみました(下記画像)。

上図右の 2020.01 の HTMLコードを今見る
<!DOCTYPE html>
<html lang="ja"><head>
<meta charset="UTF-8">
<title>Mixed Content Test</title>
</head>
<body>
<h1>Mixed Content Test Page</h1>
<h3>2020.01 IMG、 VIDEO、 AUDIO 自動変換</h3>
<h3>http:// -> https:// 【対象: <video>、 <audio>】</h3>
<table style="text-align:center" width="100%">
<tbody><tr>
<td style="vertical-align: top;background-color: antiquewhite;" width="50%">
<h2>リンク</h2>
<ul>
<li><a href="http-2.html">http-2.html</a></li>
<li><a href="http://appleplugs.com/">http://appleplugs.com</a></li>
<li><a href="https://blog.codecamp.jp">https://blog.codecamp.jp</a></li>
<li><a href="http://goinc.co.jp/">http://goinc.co.jp</a></li>
</ul>
</td>
<td style="vertical-align: top;background-color: #ecffe3;" width="50%">
<h2>画像</h2>
<br>
<img src="1.jpg" height="200px">
<img src="http://aws.o-namae.com/wp-content/uploads/2019/11/2.jpg" height="200px">
</td>
</tr>
<tr>
<td style="vertical-align: top;background-color: #ecfdfb;">
<h2>オーディオ</h2>
<br>
<p>https://</p>
<audio controls="">
<source src="horse.mp3" type="audio/mpeg">
</audio>
<br>
<p>http://</p>
<audio controls="">
<source src="https://aws.o-namae.com/wp-content/uploads/2019/11/horse.mp3" type="audio/mpeg">
</audio>
</td>
<td style="vertical-align: top;background-color: #faeeed;">
<h2>ビデオ</h2>
<video controls="" width="200">
<source src="video-https.mp4" type="video/mp4">
</video>
<video controls="" width="200">
<source src="https://aws.o-namae.com/wp-content/uploads/2019/11/video-http.mp4" type="video/mp4">
</video>
<div></div></td>
</tr>
</tbody></table>
</body></html>
今まで表示できていた <video> が真っ黒になり、 <audio> は "0秒" 表示に。 「Chrome 80」 になると <video> と <audio> タグで http:// が使われていた場合、 https:// に自動変換してアクセスする予定。外部リンクが https:// に対応していれば OK ですが、 http:// 状態では 上記画像:右 のように非表示となる予定です。もちろんユーザーがブラウザの設定で "混合コンテンツ 許可" とセットしてくれておけばいいのですが、恐らくデフォルト設定のまま使い、 混合コンテンツは BAN されると予想されますね。
そして 2020年 2月の 「Chrome 81」 がリリースされると <img> タグのリンクURLも https:// じゃなかったら ❌ になる予定です。こちらは本セクション冒頭にご紹介させて頂いた図(2012.02 想定版)の通り。自分のサイトが https:// でも、 <img> の外部リンクが http:// だと基本読み込まれないようになります。多くの場合で、ページのレイアウトが崩れたり、ユーザーに不快感を与え、直帰率を高めたり、滞在時間を減らしたりと SEO 的に悪影響が起こると想定されます。
混合コンテンツをプラグインで解決!?
現状でも Google Chrome や FireFox は混合コンテンツのページに対して "セキュア勧告" を行っていることから、 "混合コンテンツ対策" を行った、もしくは行っている方も少なくないと思います。
Webで検索すると「プラグインでサクッと解決」とか「データベースで解決」という見出しをチラホラ。 要は混合コンテンツの原因となる記事内の http:// を https:// にすべて変えちゃうという方法。

プラグイン: Better Search Replaceの事例
確かに簡単ですぐに済みそうなので魅力的な解決方法ですが、 すべて はマズイですよね。 <img src="http://〇〇/img/ttt.jpg> で読み込めていたものが、 <img src="https://〇〇/img/ttt.jpg> にすると画像元のサイトが http:// のままだったらリンクエラーになっちゃいますよね。
うかつにリンク先を https:// できないということです。
仮にプラグインで http:// を https:// に変えた後、どの URL が ❌ で どれが ○ か判定しようと思うと、 1ページずつ確認していかないといけないですね。後追いの作業となると焦りますし、画像非表示箇所が出ていると何だか SEO 的にも罪悪感。
そこで今回は "プラグイン" でも "データベース操作" でもない方法で、この 「混合コンテンツ問題」 に挑みたいと思います。
と、その前に "リンク切れ" と SEO の関係を確認しておきましょう。
リンク切れとSEOの関係

諸説色々ありますが、リンク切れは "直接" は SEO に影響しないと言われています。理由は、長い間 Webサイトを運営していればリンク環境が変わって当たり前と 検索エンジンの Google が考えているからです。
ただし、 "リンク切れ" や "アドレスミス" によって Webサイトをクロールするボットの検索が止まる、という懸念事項が存在します。あとユーザーにとってリンク切れは、期待値と反する結果なことから "直帰率" や "離脱率" につながると。
上記のリンクエラー、 "404" 専用ページを自サイトに設けるか、リダイレクト処理を施せば概ね解決できるでしょう。 GitHub は 404専用ページでリンクエラーを対策し、 Yahoo!japan はリダイレクトで対応。各サイト、リンク切れに対して何だかの対策を行っています。また WordPress はデフォルトで 404 ページを設定済み。
内部リンクは上記の方法で解決できそうですが、 "外部リンク" は難しいですね。 リンク切れのツールなどを使って定期的に見なおすしかないかもしれません、この後のプログラムを知らない場合は...
リンク切れとSEOについて参考にしたサイト、 SEOPressor
\Webサイト担当者としてのスキルが身に付く/
Pythonで混合コンテンツ対策
混合コンテンツ対策の種類
WordPress のプラグイン(SSL Insecure Content Fixer)を使って、コンテンツ内の http を https に変更した結果
今回は Python を使って実際に当サイト https://blog.codecamp.jp に存在する混合コンテンツの問題を解決したいと思いますが、その前に Google 公式などで紹介されている混合コンテンツの解決方法を確認しておきましょう。
- WordPress プラグイン: SSL Insecure Content Fixer
- WordPress プラグイン: Better Search Replace
- WordPress プラグイン: Really Simple SSL
- サービス会社: Cloudflare【有料】
- PCアプリ: HTTPS Checker【500page以上は有料】
- プログラム: bramus/mixed-content-scan
- 自分で対策
まずは WordPress のプラグイン、上図のように手っ取り早くサイト内の http:// を https:// に変更できますが、画像の読み込みが外部リンクの場合、 "画像なし" になります。セキュア勧告も消えてパット見た目はいいのですが、肝心の画像コンテンツが消えます。また読み込み的にはエラーが。つまり多少のコンテンツ犠牲を払ってでも https:// 完全対応したい場合に有効でしょう。
PCアプリの HTTPS Checker はなかなかいいのですが、 無料利用は 500ページまで。あとは検索ページ数によって月額料金が $9(〜10,000)、 $29(〜50,000) と上がっていきます。

そして実際に使ってみた感じが上図のとおりですが、上記のエラー、実は http ということで混合コンテンツエラーになっていますが、実際にアクセスすると https:// にリダイレクトされて、画像自体は読み込めています。
つまり、今回の Chrome 81 の脅威である 「画像読み込み不可」 にはならないということ。 HTTPS Checker、確かにブラウザの "セキュア勧告" の対策にはいいかもしれませんが、 2020年 2月以降には "必要ない" ことをチェックしているかもしれませんね。
あと GitHub の mixed-content-scan は、 Compose を使って操作する必要があるため今回は割愛。 Compose、 チョット難しいですよね。
そして最後に残ったのが、「自分で対策する」ということ。最初はチョット時間かかるかもしれませんが、 Python の基礎知識があれば大丈夫ですし、この先仮に テキストリンク も混合コンテンツ対象になっても大丈夫です。まずは結果から確認していきましょう。
Pythonで混合コンテンツ対策した結果

今回作成したプログラムで対策が必要と判断された画像、動画
これからご紹介するプログラムを実行した結果、 ボットが 1267ページをクロールし、 23ページ 45箇所のコンテンツを要修正と判断。実際の HTML 修正は手動としました。試しにどんなページが 2020年 2月に読み込みエラーになるか確認したところ、以下のような感じ。

2020年 2月予定の Chrome 81 を想定したページは右側(https://blog.codecamp.jp/post-31442)
今は画像が表示されていますが、 2020年 2月予定の Chrome 81 による混合コンテンツの自動https化によって、画像URL は
src="http://ecx.images-amazon.com/images/I/51AM4y1m41L._SL160_.jpg"
から
src="https://ecx.images-amazon.com/images/I/51AM4y1m41L._SL160_.jpg"
に変わると想定されます。
その結果、画像引用元の外部リンクは https:// に対応していないため、画像読み込み失敗となりサイトデザインが大きく変わる結果に。どうでしょうか、印象的に画像がなくなるとこのページ、いけてませんよね。恐らく離脱時間も早くなりますし、サイト自体の "信用度" も下がるのではないでしょうか?
今回チェックした CodeCampus は WordPress で運用していないのですが、仮に WordPress のプラグインを使って http:// を https:// に書き換えたとしたら、上図の様なエラーが想定されるでしょう。ただし、 WordPress & プラグイン の場合は、どこでエラーが起きているのかエラーチェックツールで確認しないと分からないと思います。そしてこの 2年前の記事をチェックツールが読み込む保証は... わかりませんね。つまり 先にリンク・コードを https:// に変更してからしてから エラーチェック という流れでは、不確定要素が多く、危険ということ。
今後も Webページを大事に、ユーザーを大事にしたい、 Webサイトをビジネスに生かし続けたい、と考えるなら以下の Python コードを参考にする必要があるでしょう。
尚今回のプログラムは、 CodeCampus 専用です。ご自身の Web サイトで利用する場合は、 HTML の Class 名等を適切に書き換える必要があるでしょう。今回は 1267ページを 1時間半かけてコンピューターが自動検出していきましたが、内容次第ではもう少し早くなったり、詳しいデータを抽出することも可能と考えられます。今回は文量的に必要最低限の要素の抽出およびコードとさせて頂きました。
Pythonで混合コンテンツを対策する考え方
今回のプログラムはあくまで一つの例になりますが、以下のような流れで既存の混合コンテンツが引き起こす "2020年 2月問題" を検出しました。

まず基本的に "混合コンテンツ2020.02問題" を確認するために既存サイト内の http:// を https:// に変更し、アクセス。その結果 アクセスOK であればナニもせず、 アクセスエラー だった場合はその URL と 記事URL を CSV ファイルに保存。 CSV に記録を残すことで対策が見えてきます。
"混合コンテンツ2020.02問題" ・・・ 2020年2月リリース予定の Google Chrome バージョン 81 が引き起こすであろう既存問題点を私が総称したものです。(参考ページ)
http:// を https:// に変更したり、 HTML コードを解析したりするのは Python ライブラリの BeautifulSoup というライブラリを使用します。 Webページを Python でスクレイピングしようと思うと 「BeautifulSoup」「Selenium」「Scrapy」などいくつかのツールがありますが、 BeautifulSoup が一番手軽で使いやすいかな、と思い今回のツールに選択しました。
ただし、ブログ記事内の全部の URL を抽出していくと不要な URL も検査対象に。その分時間がかかりますので、今回は "導入文" と "本文" に絞って http:// を https:// に(下記図参照)。

そして "導入文" と "本文" の <img> と <video>、 <audio> の URL を抽出。 <video>、 <audio> については <source> タグで URL を抽出できますので、 <source> で対応。そして BeautifulSoup の場合、各タグから抽出する URL について "http" か "https" か確認する機能はありませんので、その確認作業は Python の文字列機能 "http://" in link_URL でチェック。
URL の中に http:// があれば http:// を https:// に置き換え、なければ次の URL をチェック。これをブログ記事のページ毎に検索。 と、ここで一つ問題が。ブログ記事の URL が 1、 2、 3、 4 ・・・ と連番であれば簡単に制御できそうですが、実際の URL はそうはいきません。今回検索対象の https://blog.codecamp.jp については各ブログ記事を順番にチェックしようと思うと以下の方法が考えられます。
- データベースからブログ URL を Export
- 記事の管理画面からブログ URL をリストアップ
- BeautifulSoup で Webページをクロールし、各記事の URL を抽出
- 手作業で各記事の URL をコピペ
Webサイトの管理者であれば "データベース" "管理画面" が使えると思いますが、私の場合は、 CodeCampus のライター。データベースも管理画面も ❌ なので、 BeautifulSoup か手作業となり、 1200ページ以上あるサイトの中の URL チェックとなると、とても手作業では終わりません。そのため BeautifulSoup で各記事の URL を集めることに。
実際に記事の URL を集めようと思うと、いくつか方法はあると思いますが、 CodeCampus の場合は各ページ毎に 12 記事 紹介。ページ数は合計で 106ページあることがページナビに書かれていますので、ページを順番に進めながら、各ページで記事の URL を 12こ集めながら進めれば OK ということに。少し言葉ではわかりにくいので、図にしました。

一番左が一つのページで、その中の記事一覧 URL を取得。そして各記事の中の URL をチェックして、 http:// -> https:// した時にエラーとなったものは CSV に記録。 1ページ内の 12記事が終われば次のページ、ということを 106ページまでループ処理してもらいます。
それでは具体的なコードをご紹介していきます。内容を理解すれば他サイトでも応用できると思いますので、混合コンテンツやリンク切れ等で困っている方、ご参考ください。またこの "混合コンテンツ対策" は 「仕事」 になり得ると思います。フリーランスの方で 「仕事の幅を広げたい」「収入を増やしたい」と考えておられる方は、ご参考ください。
httpをhttpsに自動変更
今回のプログラムを一度に処理しようと思うと頭が混乱しますので、まずは 1つのブログ記事内の "画像 URL" を http:// チェックし、 http:// があれば https:// に自動変換 & チェックするものとします。
チェックテストする記事は以下の https://blog.codecamp.jp/font_for_programming 、混合コンテンツですね。

少しずつ記事の HTML を分解しながら、 画像の http:// を https:// に変える作業を進めていってみましょう。
上図のコードを今見る
import requests
from bs4 import BeautifulSoup
post_url = "https://blog.codecamp.jp/font_for_programming"
post_result = requests.get(post_url)
print(post_result)
src = post_result.content
soup = BeautifulSoup(src, 'lxml')
lead_text = soup.find("div", class_="p-article_lead")
print(lead_text)
try:
lead_img = lead_text.find_all("img")
except:
lead_img = []
lead_img
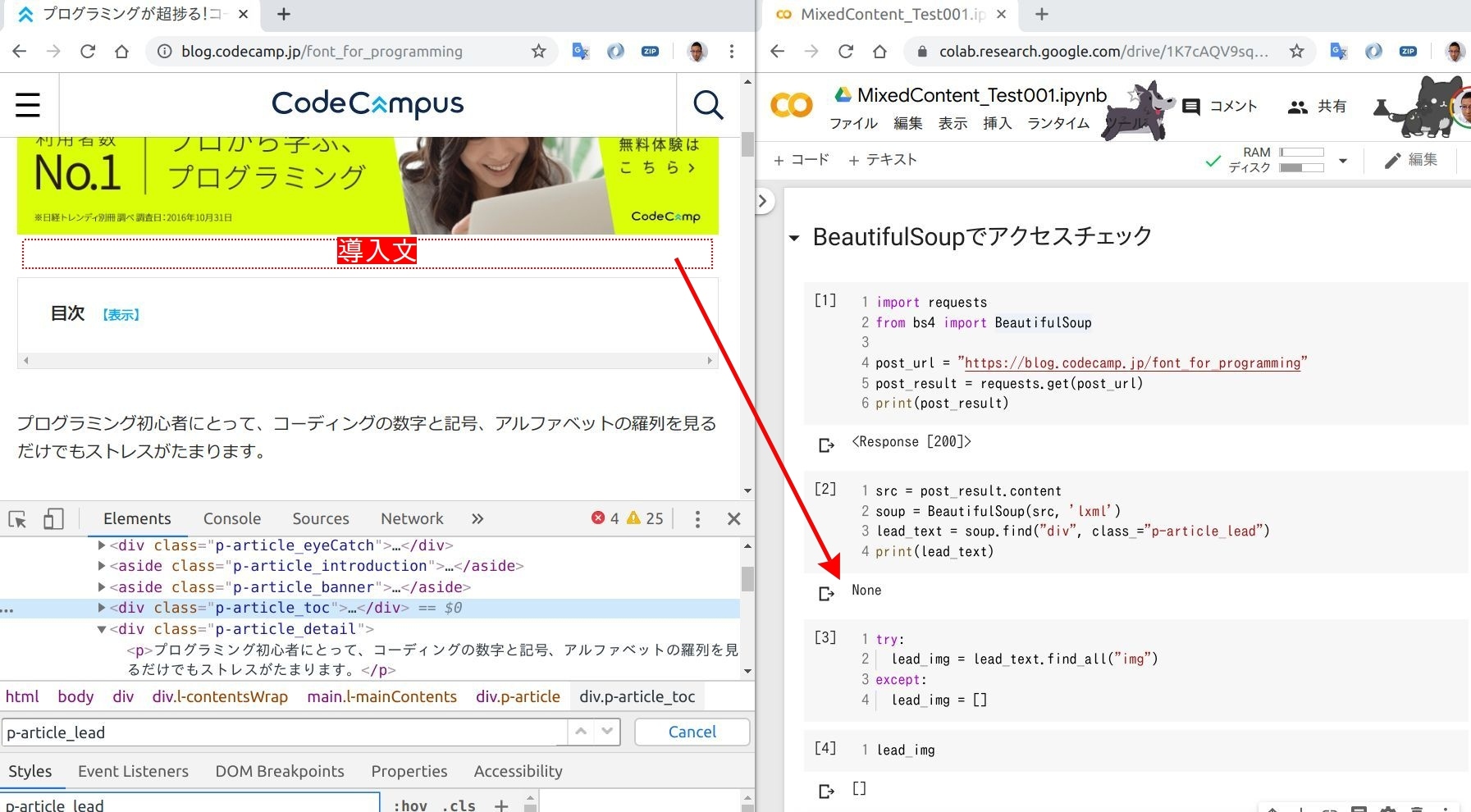
まず今回はブログ記事内の "導入文" と "本文" を分けて http:// チェックします。 1つの Webページから違う場所の HTML コードを抽出しようと思うと、 BeautifulSoup の find("div", class="〇〇") あたりの機能が効いてくるかもしれません。実際に "導入文" を抽出した結果が上図の通り。 とりあえずこの記事には "導入文" 自体がなく、 "画像" データ <img> も当然 "ない" という結果に。
【記事内の "導入文" を指定するコード】
find("div", class_="p-article_lead")
次は "本文" の中の <img>タグをチェック。
上図のコードを今見る
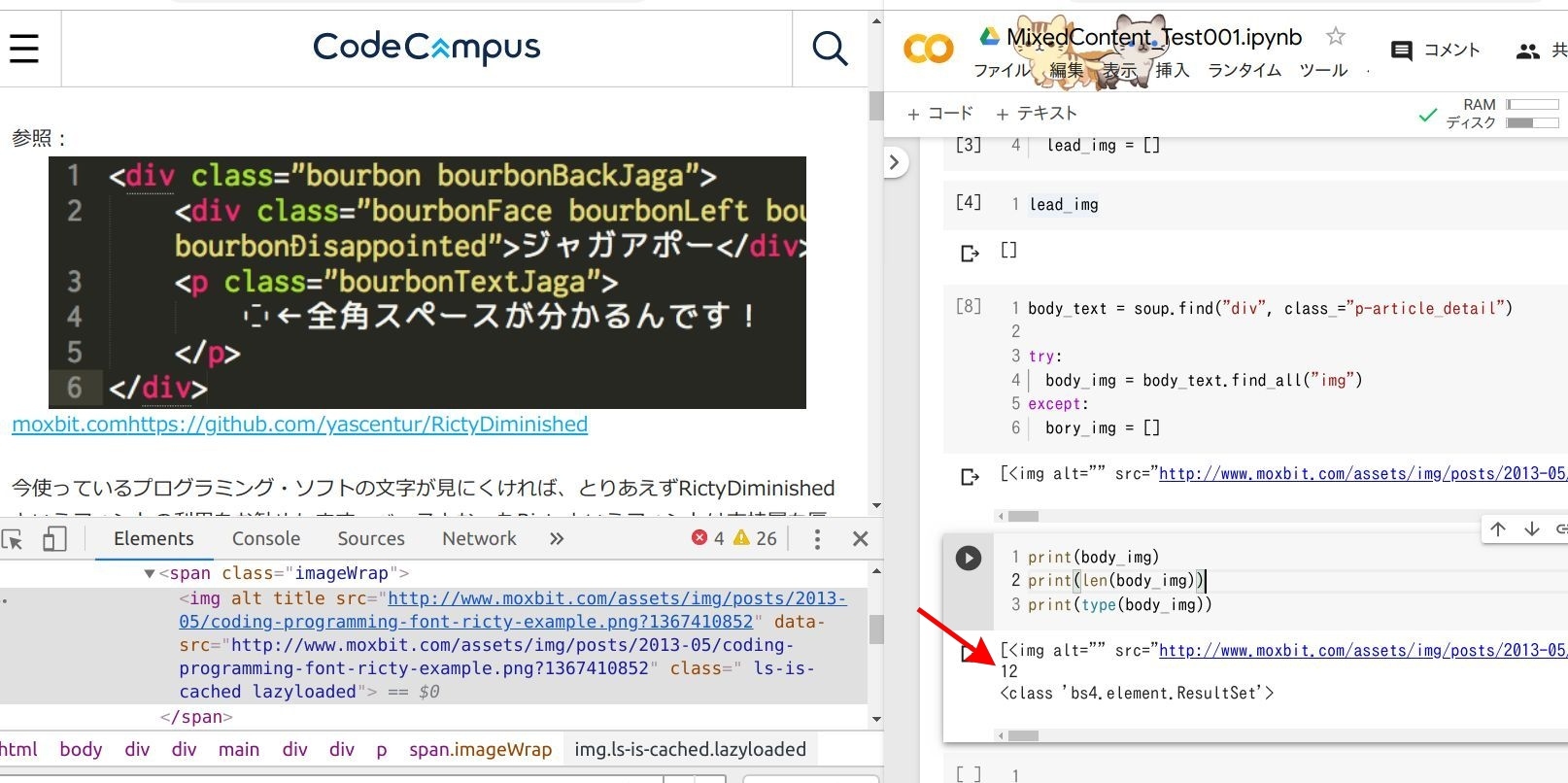
body_text = soup.find("div", class_="p-article_detail")
try:
body_img = body_text.find_all("img")
except:
bory_img = []
print(body_img)
print(len(body_img))
print(type(body_img))
すると 12 <img> があるという結果に。この <img> の URL が http:// か https:// かチェックしてみましょう。

上図のコードを今見る
img = lead_img + body_img
img_url = img[0]["src"]
print(img_url)
check = "http://" in img_url
print(check)
最初に "導入部分" と "本文" の <img> データを img に合体させて、 img[0]["src"] で 配列 img 最初 の src 部分を抽出。 その抽出結果が print(img_url) で確認できますね。
print文で URL の中身を表示させたので最初の画像 URL が http:// であることが分かりますが、コンピューターが http:// であるかどうか判断するためには 真偽値が便利。画像 URL 部分を収めた img_url 内に http:// があるかどうかは、 in を使うと調査可能。
check = "http://" in img_url
画像 URL の img_url 内に http:// があれば True 、なければ False で返されます。この http:// 判定を使って、 http:// だった場合は https:// に書き換えて、画像が読み込めるかどうかテストしてみると、 混合コンテンツ2020.02問題 をクリアできそう。
と、その前に記事内にあった 12の 画像URL 全てを http:// チェックしていませんので、 ループ文で すべての画像URL を http:// チェック。

上図のコードを今見る
img_url_len = len(img)
l = 0
while l < img_url_len:
img_link = img[l]["src"]
print(img_link)
check = "http://" in img_link
print(check)
l = l + 1
2つだけ http:// みたいですね。それでは http:// を httpe:// に書き換えてチェックしてみましょう。

上図のコードを今見る
img_link = "http://www.moxbit.com/assets/img/posts/2013-05/coding-programming-font-ricty-example.png?1367410852"
img_link = img_link.replace('http://', 'https://')
print(img_link)
img_req = requests.get(img_link, timeout=2)
img_result = img_req.get()
print("http -> https 変換後のアクセス結果:" + str(img_result))
http:// の https:// への書き換え自体は replace() で OK。
そして https:// に書き換えた URL でアクセスしてみると読み込みエラーに...このエラーは try:文で対応します。
https:// にアクセスしても読み込みに時間がかかる場合もあります。本来は https:// でアクセスできるのに接続時間的にエラーとなると http:// -> https:// の精度が落ちます。そのために timeout を設定。

上図のコードを今見る
try:
img_req = requests.get(img_link, timeout=2)
img_result = img_req.get()
print("http -> https 変換後のアクセス結果:" + str(img_result))
except:
print("エラー: " + img_link)
import csv
try:
img_req = requests.get(img_link, timeout=2)
img_result = img_req.get()
print("http -> https 変換後のアクセス結果:" + str(img_result))
except:
print("エラー: " + img_link)
with open('Error-URL.csv', 'a') as csvFile:
writer = csv.writer(csvFile)
writer.writerow(["imglink", img_link, post_url])
csvFile.close()
!cat Error-URL.csv
http:// -> https:// の変換テストを try:文でテストした結果、うまくエラーハンドリングできました。この http:// -> https:// でアクセスできない 画像URL が 混合コンテンツ2020.02問題に直面すると考えられますので、 対象となる 画像URL と その画像が表示されているブログ記事の URL を CSV に記録(上図最下段)。
ここまでの処理フローで 画像URL 一つに対しての処理。ページ内の 12 画像URL に対して同様の処理を行うようにループ文で処理していきます。

上図のコードを今見る
import requests
from bs4 import BeautifulSoup
post_url = "https://blog.codecamp.jp/font_for_programming"
post_result = requests.get(post_url)
src = post_result.content
soup = BeautifulSoup(src, 'lxml')
lead_text = soup.find("div", class_="p-article_lead")
try:
lead_img = lead_text.find_all("img")
except:
lead_img = []
body_text = soup.find("div", class_="p-article_detail")
try:
body_img = body_text.find_all("img")
except:
bory_img = []
img = lead_img + body_img
img_url_len = len(img)
l = 0
roop_time = 1
while l < img_url_len:
print("\nループ回数:" + str(roop_time))
img_link = img[l]["src"]
print("チェック画像URL:" + img_link)
check = "http://" in img_link
#print(check)
if check:
img_link = img_link.replace('http://', 'https://')
print("http:// -> https:// : " + img_link)
try:
img_req = requests.get(img_link, timeout=2)
img_result = img_req.get()
print("OK: " + img_link)
except:
print("エラー: " + img_link)
with open('Error-URL.csv', 'a') as csvFile:
writer = csv.writer(csvFile)
writer.writerow(["imglink", img_link, post_url])
csvFile.close()
else:
pass
l = l + 1
roop_time = roop_time + 1
ここまで各ステップで進めてきた while、 if、 try を組み合わせて 1ページ内の画像URL を http チェック。 https 変換後のアクセス結果も確認できていいですね。
あとはこの <img> を応用して <video>、 <audio> も http:// チェックできれば OK。恐らく BeautifulSoup の抽出タグを <img> から video、 audio に変換すれば OK なので、この 画像URL 抽出プログラムを関数化しておきます。
関数 img() の Python コード
def img():
post_url = "https://blog.codecamp.jp/font_for_programming" #crawl() 使用時は消すべし
post_result = requests.get(post_url)
src = post_result.content
soup = BeautifulSoup(src, 'lxml')
lead_text = soup.find("div", class_="p-article_lead")
try:
lead_img = lead_text.find_all("img")
except:
lead_img = []
body_text = soup.find("div", class_="p-article_detail")
try:
body_img = body_text.find_all("img")
except:
body_img = []
img = lead_img + body_img
if img == []:
pass
else:
img_url_len = len(img)
l = 0
#roop_time = 1
while l < img_url_len:
#print("\nループ回数:" + str(roop_time))
img_link = img[l]["src"]
print("チェック画像URL:" + img_link)
check = "http://" in img_link
#print(check)
if check:
img_link = img_link.replace('http://', 'https://')
print("http:// -> https:// : " + img_link)
try:
img_req = requests.get(img_link, timeout=2)
img_result = img_req.get()
print("OK: " + img_link)
except:
print("エラー: " + img_link)
with open('Error-URL.csv', 'a') as csvFile:
writer = csv.writer(csvFile)
writer.writerow(["imglink", img_link, post_url])
csvFile.close()
else:
pass
l = l + 1
#roop_time = roop_time + 1
関数 video() の Python コード
def video():
post_url = "https://blog.codecamp.jp/programming-camenrider-android-app" #crawl() 使用時は消すべし
post_result = requests.get(post_url)
src = post_result.content
soup = BeautifulSoup(src, 'lxml')
lead_text = soup.find("div", class_="p-article_lead")
try:
lead_video = lead_text.find_all("source")
except:
lead_video = []
body_text = soup.find("div", class_="p-article_detail")
try:
body_video = body_text.find_all("source")
except:
body_video = []
video = lead_video + body_video
if video == []:
print("video tag nothing★")
else:
video_url_len = len(video)
ll = 0
#roop_time = 1
while ll < video_url_len:
#print("\nループ回数:" + str(roop_time))
video_link = video[ll]["src"]
print("チェック動画URL:" + video_link)
check2 = "http://" in video_link
#print(check)
if check2:
video_link = video_link.replace('http://', 'https://')
print("http:// -> https:// : " + video_link)
try:
video_req = requests.get(video_link, timeout=2)
video_result = video_req.get()
print("OK: " + video_link)
except:
print("エラー: " + video_link)
with open('Error-URL.csv', 'a') as csvFile:
writer = csv.writer(csvFile)
writer.writerow(["videolink", video_link, post_url])
csvFile.close()
else:
pass
ll = ll + 1
#roop_time = roop_time + 1
ページをクロール

1記事内の http:// チェックはできましたので、次は順番に記事をリストアップして、順番に読み込んでいくプロセスが必要です。
イメージとしては上図のような感じで、ページ1 〜 106 までを順番にクロールしながら、各ページのブログ記事を確認。ループ文で処理できそうですね。
とりあえず 106ページまでループ処理できるかテスト

上図の Python コード を今見る
post_page = 1
while post_page < 107:
page_url = "https://blog.codecamp.jp/page/" + str(post_page)
print(str(post_page) + "ページ目")
post_page = post_page + 1
最初のページから最後のページまでクロールできそうですね。あとは各ページ内のブログ記事URL をリストアップし、 http:// チェックできれば OK でしょう。

上図の Python コード を今見る
page_url = "https://blog.codecamp.jp" # 1 -> 106 ページまでクロールする時はけすべし
def crawl():
result = requests.get(page_url)
src = result.content
soup = BeautifulSoup(src, 'lxml')
main = soup.find('main')
links = main.find_all("a", class_="c-post_eyeCatchLink")
links_number = len(links)
n = 0
crowl_number = 1
while n < links_number:
href = links[n]['href']
post_url = "https://blog.codecamp.jp" + href
print(post_url)
with open('CrawledPage.csv', 'a') as csvFile:
writer = csv.writer(csvFile)
writer.writerow([str(crowl_number), "チェックしたURL", post_url])
csvFile.close()
img()
time.sleep(1)
video()
time.sleep(1)
print(str(crowl_number) + "ページ目終わり\n")
n = n + 1
crowl_number = crowl_number + 1
試しに最初のページの ブログ記事一覧 URL を読み込み、その URL を "CrawledPage.csv" に保存。
そして最初のブログ記事 URL に対して 関数 img() と 関数 video() を実行。 http:// エラーがあった URL は img() や video() で決めた CSV に保存されるはずです。

しかし、 crawl() を実行してみても、 リンクエラーのプリント文や CSV は作成されていません。いろいろ調べていくと、 img() や video() に必要なブログ記事の URL が craw() から渡されていないことが分かります。これは 関数 間で変数を使用する時に必要な "グローバル変数" が定義されていないため。

上図の Python コード を今見る
page_url = "https://blog.codecamp.jp" # 1 -> 106 ページまでクロールする時はけすべし
def crawl():
global post_url
result = requests.get(page_url)
src = result.content
soup = BeautifulSoup(src, 'lxml')
main = soup.find('main')
links = main.find_all("a", class_="c-post_eyeCatchLink")
links_number = len(links)
n = 0
crowl_number = 1
while n < links_number:
href = links[n]['href']
post_url = "https://blog.codecamp.jp" + href
print(post_url)
with open('CrawledPage.csv', 'a') as csvFile:
writer = csv.writer(csvFile)
writer.writerow([str(crowl_number), "チェックしたURL", post_url])
csvFile.close()
img()
time.sleep(1)
video()
time.sleep(1)
print(str(crowl_number) + "ページ目終わり\n")
n = n + 1
crowl_number = crowl_number + 1
1ページ内のブログ記事リストをクロールする crawl() 内にグローバル変数 global post_url を設定。そして改めて crawl() を実行してみると下記のように、 http:// チェックが行われていることが確認できます。
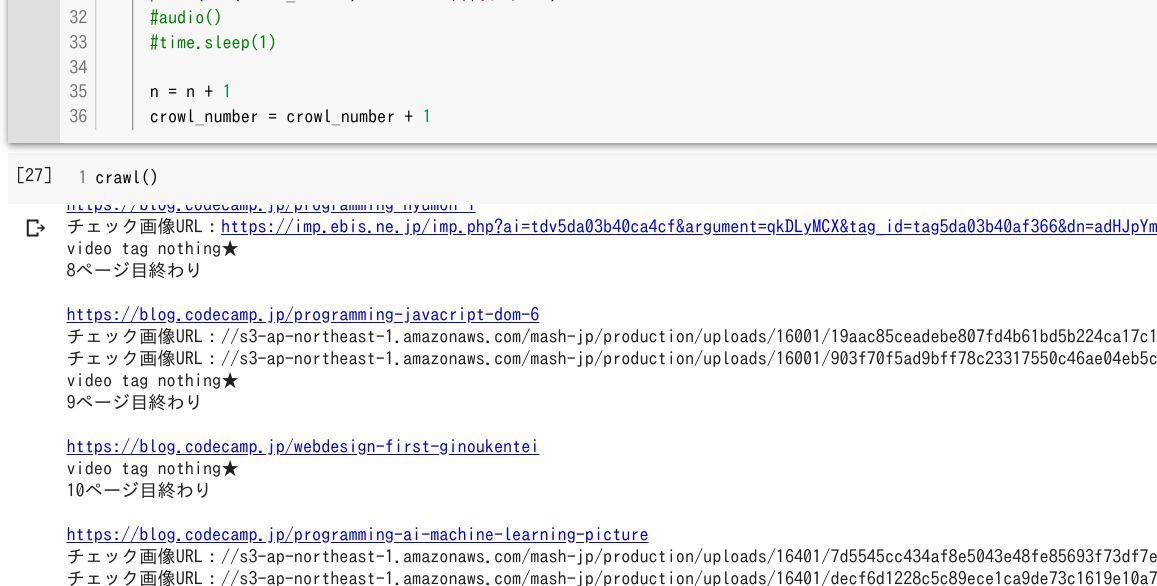
クーロルを行った ブログ記事URL は "CrawledPage.csv" 内に保存され、 http:// エラーについてはなんと 0 でした。それではいよいよ 1ページから 106ページ目までを順番にクロールしてもらうようにプログラムを整理してみましょう。
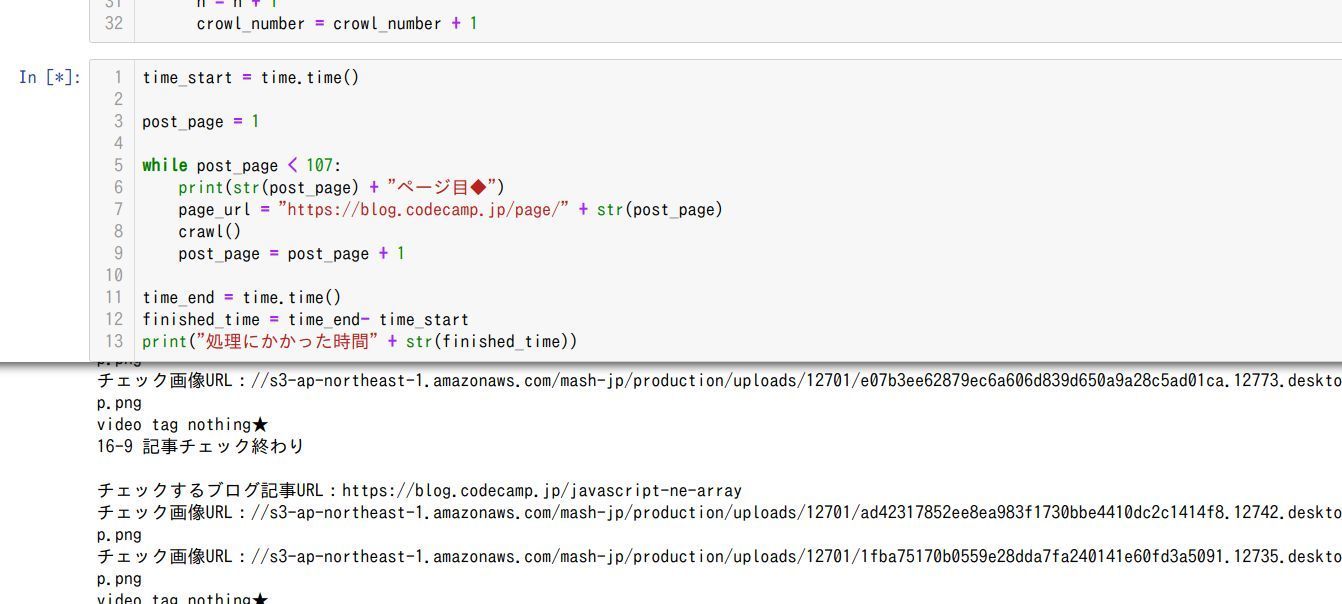
上図の Python コード を今見る
time_start = time.time()
post_page = 1
while post_page < 107:
print(str(post_page) + "ページ目◆")
page_url = "https://blog.codecamp.jp/page/" + str(post_page)
crawl()
post_page = post_page + 1
time_end = time.time()
finished_time = time_end- time_start
print("処理にかかった時間" + str(finished_time))
クロール関数 crawl() を 1ページ目から 107ページ目までクロールするように上図のようにループ文を組めば OK ですね。
プログラムを実行すると 1時間半程度終了までに時間がかかります。場合によってはブラウザの Colab が落ちますので、ローカル環境の Jupyter Notebook で実行した方が安定するかもしれません。
プログラムの実行
さて今回作成したプログラムを実際に実行してみると、 Google Colab の環境では途中にダウンしてしまいます。ローカル環境に接続して、作成した Jupyter Notebook を実行してみました。

すると意外に <img> のエラーが多く、合計で 166 の URL が http:// から https:// に変換しても読み込めなかったとエラー。 しかし、エラーリストからリクエストエラーだった画像URL にアクセスしてみると読み込めるモノも。
【実際には読み込めるのに 読み込み不可でエラーとなった例】
https://s3-ap-northeast-1.amazonaws.com/mash-jp/production/uploads/11201/c3209d781693b7c682bbc43dada616496bae40b1.11231.desktop.jpg
http:// から https:// に変換して、アクセスエラーだった URL を再度チェックしてみました。
httpチェックの再検証

http:// から https:// に変換した時のアクセス・エラーは、再確認したところ 45 の URL がアクセスエラーに。今度は本当にエラーで、 URL をブラウザにコピペしても ❌ でした。最初のプログラム実行時に http:// -> https:// でエラーが出た理由は、はっきりわかりませんが、実行結果を検証することで精度を上げられたと思います。

再検証している様子
code: GitHub
再検証した Python コード を今見る
import pandas as pd
from pandas import read_csv
df = read_csv("Error-URL.csv")
print(df.head())
col_Names = ["type", "LINK", "POST_URL"]
csv_file = pd.read_csv("Error-URL.csv", names = col_Names)
df_LINK = csv_file[["LINK"]]
print(df_LINK[:5])
df_POST_URL = csv_file[["POST_URL"]]
print(df_POST_URL[:5])
LINK = df_LINK["LINK"].astype(str)
POST_URL = df_POST_URL["POST_URL"].astype(str)
s = LINK[0]
print(s)
print(type(s))
import requests
import csv
import time
loop_time = 0
for s in LINK:
post_url = POST_URL[loop_time]
try:
check_http_url_result = requests.get(s, timeout=7)
if check_http_url_result.url == s:
print("URL 一緒: " + s)
with open('check_http_url_result.csv', 'a') as csvFile:
writer = csv.writer(csvFile)
writer.writerow(["OK", s, post_url])
csvFile.close()
loop_time = loop_time + 1
else:
print("リダイレクトした:" + s + " -> " + check_http_url_result.url)
with open('check_http_url_result.csv', 'a') as csvFile:
writer = csv.writer(csvFile)
writer.writerow(["リダイレクトあり", s , check_http_url_result.url, post_url])
csvFile.close()
loop_time = loop_time + 1
except:
print("チェック URL: " + s + " アクセスできなかったよ★" )
with open('check_http_url_result.csv', 'a') as csvFile:
writer = csv.writer(csvFile)
writer.writerow(["エラーでした", s, post_url])
csvFile.close()
loop_time = loop_time + 1
最初のプログラムで出力された 「http:// -> https:// エラーファイル」 の 画像URL をピックアップし、再検証。
CSVから特定の "列" を文字列として抽出するために Pythonライブラリの Pandas を使用。
つまり 混合コンテンツ2020.02問題 に対して、こちらの 45 URL 、 23 記事を早急に再検証し、 View の多いブログ記事から優先して対処すればいいことが分かりました。
混合コンテツ問題の概要を動画で確認
本稿のダイジェスト版です。
まとめ
今回は一つの ブログ をきっかけに 混合コンテンツ の http:// 対策を行いました。
プログラムの作成から完了までおおよそ 8時間、 ページあたりの時間に換算すると 1ページあたり 2.6分。どうでしょうか人間がやった方が早いでしょうか?コンピューターがやった方が早いでしょうか?
恐らくコンピューターの方に軍配が上がると思いますし、コンピューターの場合は 1,000ページでも 100,000ページでも処理にかかる時間は一定で、基本的にミスもないと考えられます。
巷では Pythonの学習本に 「退屈なことは Python にやらせよう」 という本がヒットしていますが、今回の 混合コンテンツ こそ Python ではないでしょうか?
また今後 Google の方針が変わりテキストリンクも https:// じゃないと... となっても今回のプログラムを使えば特別ビビることもありません。また <img> じゃなくて <a> タグをチェックしたら、リンクエラーも確かにチェックできました。
アレコレSEOに時間やお金をかけられるなら、一度 Python で Webサイト全体を見直してみませんか?
「Python,,,ちょっとハードル高いんだよな...」「Pythonは AI や 人工知能以外にもいろいろ使えるんだな...」 と Python に興味を持ちつつ学習を躊躇されている方、どうでしょうかプログラミングスクールで Python を体系的に学習するというのは?
Pythonの学習本やチュートリアル動画は多数公開されていますが、手早く正確に学習しようと思うと "誰かから教えてもらう" というのが一番ではないでしょうか?
「CodeCamp? オンラインで本当に身につくのかな?」「オンライン、マンツーマン、緊張しそう...」 プログラミングレッスンについては色々な不安があると思いますが、 CodeCamp ではその "不安" を事前に体験レッスンで確認することができます。
もちろん体験レッスンは "無料" で運営していますので、 Python とかプログラミングとかご興味ある方は 公式ページ より確認してみてください。







- この記事を書いた人
- オシママサラ









{kind=link}
{kind=link}