- 更新日: 2020年01月30日
- 公開日: 2020年01月29日
【Python入門】スクレイピングを使って自動的にWebページからたくさんファイルをダウンロードする方法

データ収集や毎日の生活の自動化のために Webページからファイルを自動的にダウンロードしたい時、ありますよね。
今回は Python ライブラリの Selenium を使って、 225このファイルを自動的にダウンロードしてみました。
【今回スクレイピングで使用するブラウザ】
・ FireFox
・ Google Chrome
【Python入門】スクレイピングを使って自動的にWebページからたくさんファイルをダウンロードする方法
スクレイピングを使って自動的にファイルをダウンロードする方法
225の CSV ファイルを自動的にダウンロードしている様子の動画(30min)
"スクレイピング" というと Webページからデータを取得する時に使用する手法。一般的に Python でスクレピングをする時には、以下のライブラリやフレームワークが使用されると思います。
- Beautifulsoup
- Selenium
- Scrapy
"Scrapy" はフレームワークで高機能な反面、他の 2つより取り扱いが少し難しいため今回はパスします。 Beautifulsoup については、ネット上の情報量も多く扱いやすいのですが "クリック" や "スクロールダウン" などのブラウザ操作を行うことは不可能です。よって今回は、比較的情報量も多く、"クリック" や "スクロールダウン" などのブラウザ操作できる "Selenium" を使って Webページからファイルをダウンロードしていきたいと思います。
| 初心者向き | 情報量 | クリック操作 | スピード | 機能 | |
|---|---|---|---|---|---|
| Beautifulsoup | ○ | ○ | ❌ | ○ | ○ |
| Selenium | ○ | ○ | ○ | △ | ○ |
| Scrapy | △ | △ | ❌ | ○ | ◎ |
プログラムがボタンをクリックしてファイルをダウンロードする方法

スクレイピングの技術を使って、 Webページ上からファイルをダウンロードする方法は 「クリックさせてダウンロード」する方法と 「URLを読み込んでダウンロード」させる方法の2つ。まずは 「クリックしてダウンロード」 から実行してみたいと思います。
Selenium を使って Webページ上のボタンを "クリック" するには、 click() 機能を使えば OK。 ただし、どの HTML 要素をクリックさせるか、という点がポイントになります。
例えば下記のようなページでは、 a タグを click() させる必要があるでしょう。
「スクレイピング × FireFox × ダウンロード」のパターン

普段のパソコンやスマホの操作でクリックしているところは "文字" であっても、プログラム上は aタグが反応。よってプログラムにも aタグをクリックしてもらう必要がありますね。
それでは実際に上記ページを、まずは FireFoxでスクレイピングしてみたいと思います。
上図のURL
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import os
import time
download_folder = "/home/oshimamasara/★dev/3/file"
profile = webdriver.FirefoxProfile()
profile.set_preference("browser.download.folderList", 2)
profile.set_preference("browser.download.dir", download_folder)
profile.set_preference("browser.download.manager.showWhenStarting", False)
profile.set_preference("browser.download.manager.alertOnEXEOpen", False)
profile.set_preference("browser.download.manager.closeWhenDone", False)
profile.set_preference("browser.helperApps.neverAsk.saveToDisk", "application/x-msdownload,application/octet-stream")
try:
browser = webdriver.Firefox(profile)
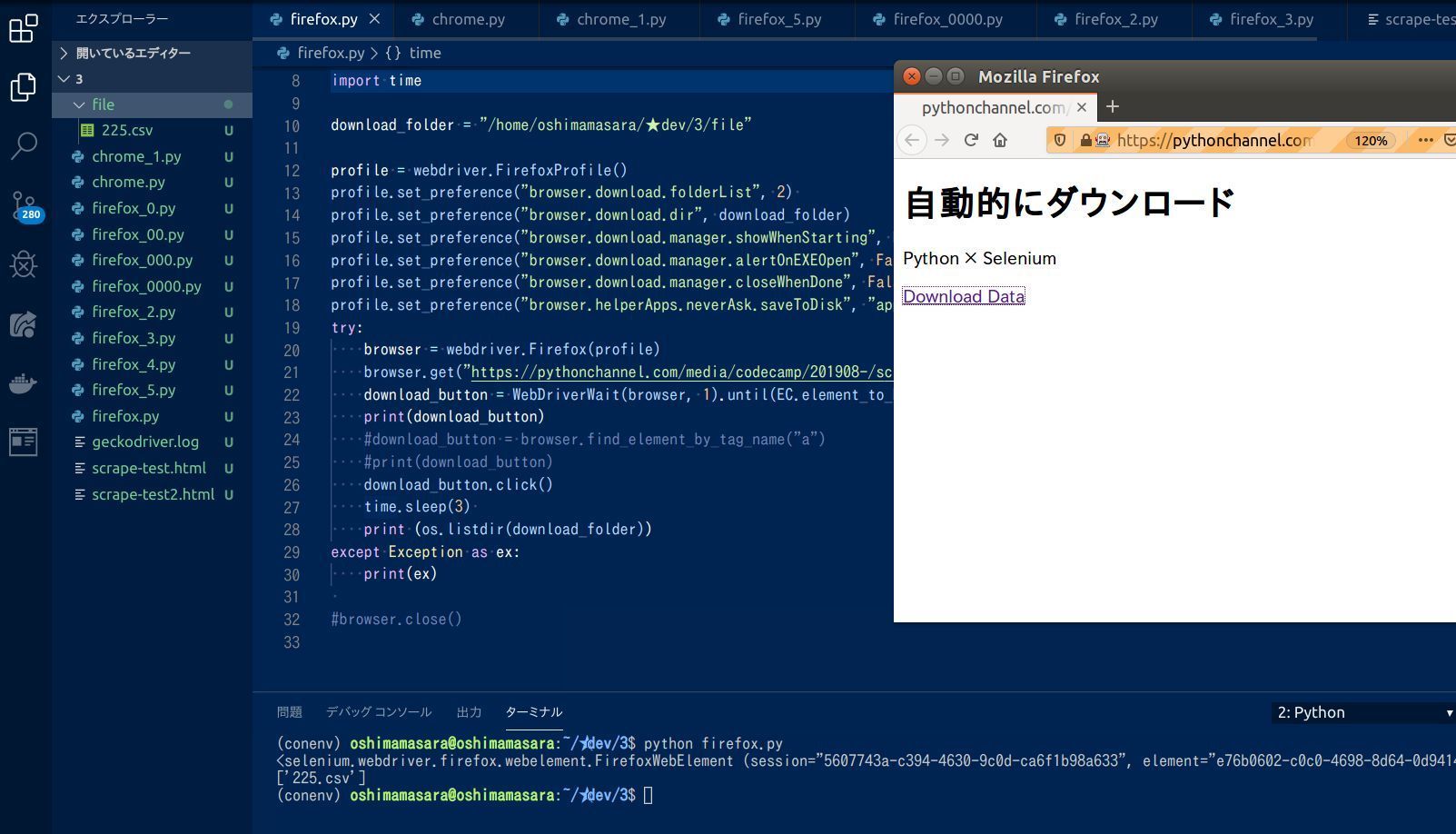
browser.get("https://pythonchannel.com/media/codecamp/201908-/scrape-test.html")
download_button = WebDriverWait(browser, 1).until(EC.element_to_be_clickable((By.XPATH, "/html/body/a")))
print(download_button)
#download_button = browser.find_element_by_tag_name("a")
#print(download_button)
download_button.click()
time.sleep(3)
print (os.listdir(download_folder))
except Exception as ex:
print(ex)
上記プログラムをローカル環境で実行すると、現在の作業ディレクトリに file というフォルダが自動的に作られて、その中に Webページ上の a タグのリンク内容、つまり CSVファイルがダウンロードされています。
a タグ内の要素、つまり URL の抽出には、今回
WebDriverWait(browser, 1).until(EC.element_to_be_clickable((By.XPATH, "/html/body/a")))
を使っていますが、
browser.find_element_by_tag_name("a")
でも実行することができます(下図参照)。

上図のURL
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import os
import time
download_folder = "/home/oshimamasara/★dev/3/file"
profile = webdriver.FirefoxProfile()
profile.set_preference("browser.download.folderList", 2)
profile.set_preference("browser.download.dir", download_folder)
profile.set_preference("browser.download.manager.showWhenStarting", False)
profile.set_preference("browser.download.manager.alertOnEXEOpen", False)
profile.set_preference("browser.download.manager.closeWhenDone", False)
profile.set_preference("browser.helperApps.neverAsk.saveToDisk", "application/x-msdownload,application/octet-stream")
try:
browser = webdriver.Firefox(profile)
browser.get("https://pythonchannel.com/media/codecamp/201908-/scrape-test.html")
#download_button = WebDriverWait(browser, 1).until(EC.element_to_be_clickable((By.XPATH, "/html/body/a")))
#print(download_button)
download_button = browser.find_element_by_tag_name("a")
print(download_button)
download_button.click()
time.sleep(3)
print (os.listdir(download_folder))
except Exception as ex:
print(ex)
結果は同じなのに異なる2つのコード、 aタグの読み込み方が異なります。
最初の
WebDriverWait(browser, 1).until(EC.element_to_be_clickable((By.XPATH, "/html/body/a")))
は、 WebDriverWait() によって a タグが Webページ上で読み込まれるまで 1秒 待ってくれます。 もしページの読み込みに時間がかかって、 1秒を超えるとタイムアウト判定されます。 5秒や 10秒など任意の数字に変えて実行すると、プログラムが a タグを確実に読み込んでくれるでしょう。
上記のコードに対して
browser.find_element_by_tag_name("a")
は、待つ機能がありません。なので Webページのボリュームが多かったり、通信環境が悪かったりすると、 a タグの読み込みエラーになる可能性があります。つまり 2つのコードの違いは、スクレイピングの "正確性" に関係してくる内容。後者の場合でも time.sleep(10) などを使うと、スクレイピングの読み込みエラーを減らすことはできますので、一概にどっちを使うべき、という状況ではなさそうです。
あと画像のコードを確認すると profile に関連することが、 8行も書かれています。これは FireFox 特有の問題で、通常 FireFox を使って Webページからファイルをダウンロードする時、下記のようなウィンドウが表示されると思います。
下記画像URL: https://pythonchannel.com/media/codecamp/201908-/scrape-test.html

普段なら "OK" ボタンをクリックしてファイルのダウンロードを実行していると思いますが、この "OK" ボタン、 Selenium では押すことができません。なので FireFox の設定を変更するように、プログラムで ウィンドウ"非表示" に制御。
【FireFoxの設定内容について】
profile.set_preference("browser.download.folderList", 2)
デフォルトの値は 1 です。 2 にすることで FireFox ダウンロード実行時、ダウンロード・フォルダ以外のフォルダを使用することが可能に。今回は作業ディレクトリの file フォルダを利用するために 2 に設定。
profile.set_preference("browser.download.dir", download_folder)
このプログラムで実行される時のファイルのダウンロード先を指定。 「download_folder = 現在の作業ディレクトリの file フォルダ」 を指しますので、ダウンロード・フォルダではなく、 fileフォルダにダウンロード。
profile.set_preference("browser.download.manager.showWhenStarting", False)
デフォルトでは True ですが、 False に変更。こちらはダウンロード開始時にウィンドウを表示するかどうか、という項目
profile.set_preference("browser.download.manager.alertOnEXEOpen", False)
こちらもデフォルトでは True ですが、 False に変更。 Windowsマシンに関係するコードで、 .exe ファイルの時の挙動を設定。
profile.set_preference("browser.download.manager.closeWhenDone", False)
こちらもデフォルトでは True ですが、 False に変更。ダウンロード完了時のウィンドウ制御に関するもの。
profile.set_preference("browser.helperApps.neverAsk.saveToDisk", "application/x-msdownload,application/octet-stream")
こちらはダウンロード完了後に、ダウンロードマネージャーが管理する一時ファイルを削除するかどうかに関する項目。 OS によってデフォルト値は違って、Mac は false 。 他は、 True。 今回の場合は、 "保存" に設定されていますね。
「スクレイピング × Crome × ダウンロード」のパターン
先程までは FireFox を使って、「スクレイピング&ダウンロード」を実行していました。次は Google Chrome を使ってファイルを自動ダウンロードしたいと思います。

上図のURL
from selenium import webdriver
import os
import time
import csv
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
url = "https://pythonchannel.com/media/codecamp/201908-/scrape-test.html"
driver.get(url)
download_button = WebDriverWait(driver, 5).until(EC.element_to_be_clickable((By.XPATH, "/html/body/a")))
print(download_button)
download_button.click()
time.sleep(3)
Chrome の場合は、 FireFox と違ってブラウザの設定を変更しなくても、デフォルトの状態でファイルをダウンロード可能。 driver = webdriver.Chrome() とすることでブラウザを Chrome に指定できます。
プログラムでURLにアクセスしてファイルをダウンロード
先程までは Selenium の click() を実行して、ファイルのダウンロードを行っていましたが、場合によっては URL でダウンロードを制御したい場合も出てくるでしょう。例えば複数のファイルをダウンロードするときには click() より "URL" を使ってダウンロードする方が便利。
まずは先ほどと同じように FireFox から "URL" を使ってダウンロードしてみます。
上図のURL
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import os
import time
import urllib.request
download_folder = "/home/oshimamasara/★dev/3/file"
profile = webdriver.FirefoxProfile()
profile.set_preference("browser.download.folderList", 2)
profile.set_preference("browser.download.dir", download_folder)
profile.set_preference("browser.download.manager.showWhenStarting", False)
profile.set_preference("browser.download.manager.alertOnEXEOpen", False)
profile.set_preference("browser.download.manager.closeWhenDone", False)
profile.set_preference("browser.helperApps.neverAsk.saveToDisk", "application/x-msdownload,application/octet-stream")
try:
browser = webdriver.Firefox(profile)
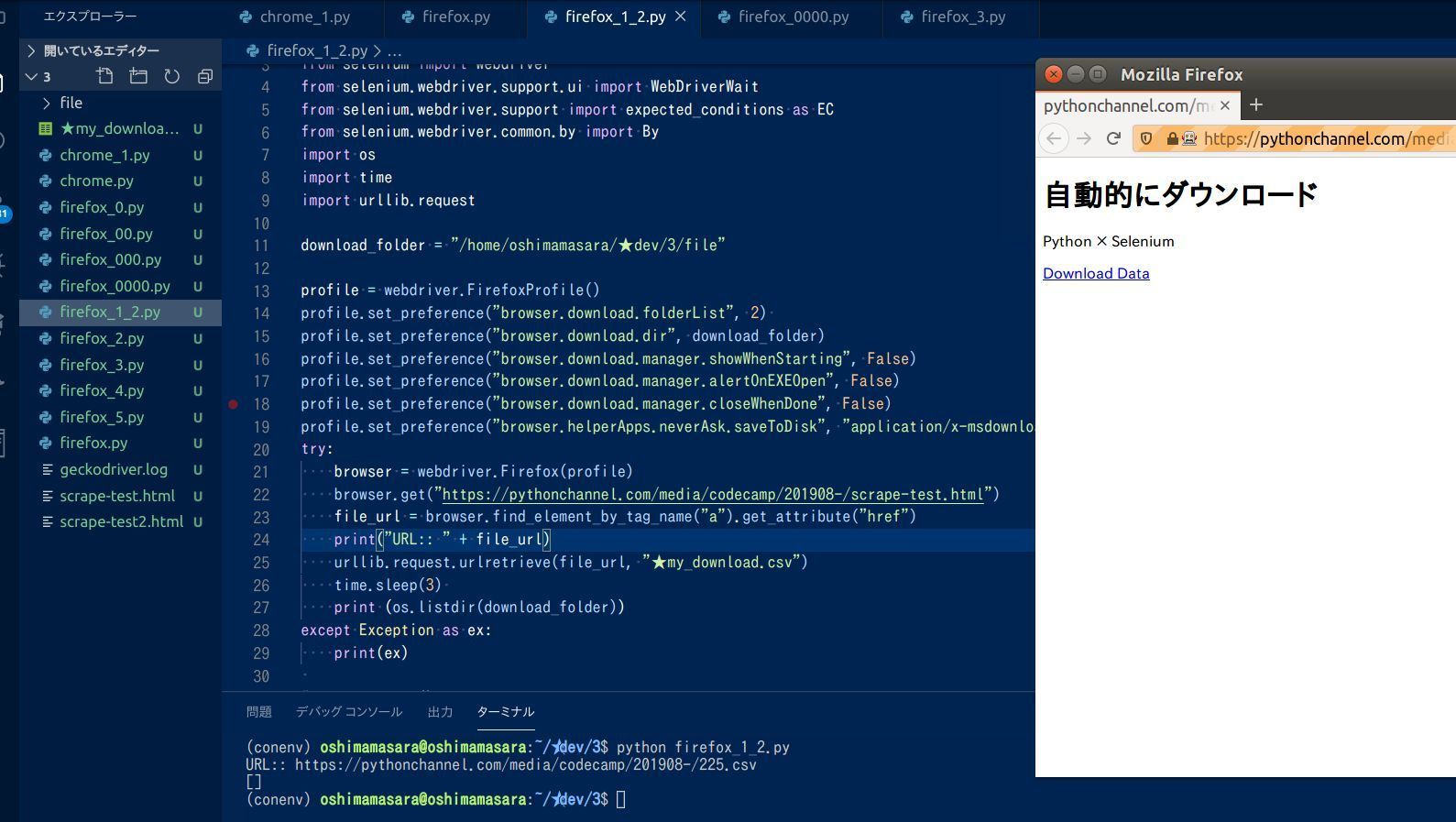
browser.get("https://pythonchannel.com/media/codecamp/201908-/scrape-test.html")
file_url = browser.find_element_by_tag_name("a").get_attribute("href")
print("URL:: " + file_url)
urllib.request.urlretrieve(file_url, "★my_download.csv")
time.sleep(3)
print (os.listdir(download_folder))
except Exception as ex:
print(ex)
先ほどの click() の時から変わったところとしては、 23行目から。 ダウンロード対象のファイル URL は、 23行目の
file_url = browser.find_element_by_tag_name("a").get_attribute("href")
で定められています。そしてその URL を元に urllib.request.urlretrieve(〇〇, △△) を使い、ファイルをダウンロード。 ○○は ダウンロード対象のファイル URL、 △△は保存するファイル名になります。この 2つの文字を設定しておかないと正しくダウンロードされません。
ダウンロードされたファイルは、先ほど同様に file ディレクトリに保存する設定としていましたが、 urllib.request.urlretrieve(〇〇, △△) が Selenium とは関係ないために profile で設定したブラウザ環境を無視します。そのためファイルは file ディレクトリではなく、現在の作業ディレクトリにダウンロード。 Chrome についても FireFox と同じようなコードで URL からファイルをダウンロードできますね(下図参照)。

ダウンロードしたいファイルの URL を読み込んで、ダウンロードしている様子
上図のURL
from selenium import webdriver
import os
import time
import csv
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import urllib.request
driver = webdriver.Chrome()
url = "https://pythonchannel.com/media/codecamp/201908-/scrape-test.html"
driver.get(url)
file_url = driver.find_element_by_tag_name("a").get_attribute("href")
urllib.request.urlretrieve(file_url, "□my_download.csv")
time.sleep(3)
複数のファイルを自動でダウンロードする方法
先ほどの 『URL からファイルをダウンロード』 する方法を応用すると、複数のファイルも一度にダウンロードできます。
上図のURL
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import os
import time
import requests
import urllib.request
try:
browser = webdriver.Firefox()
browser.get("https://pythonchannel.com/media/codecamp/201908-/scrape-test2.html")
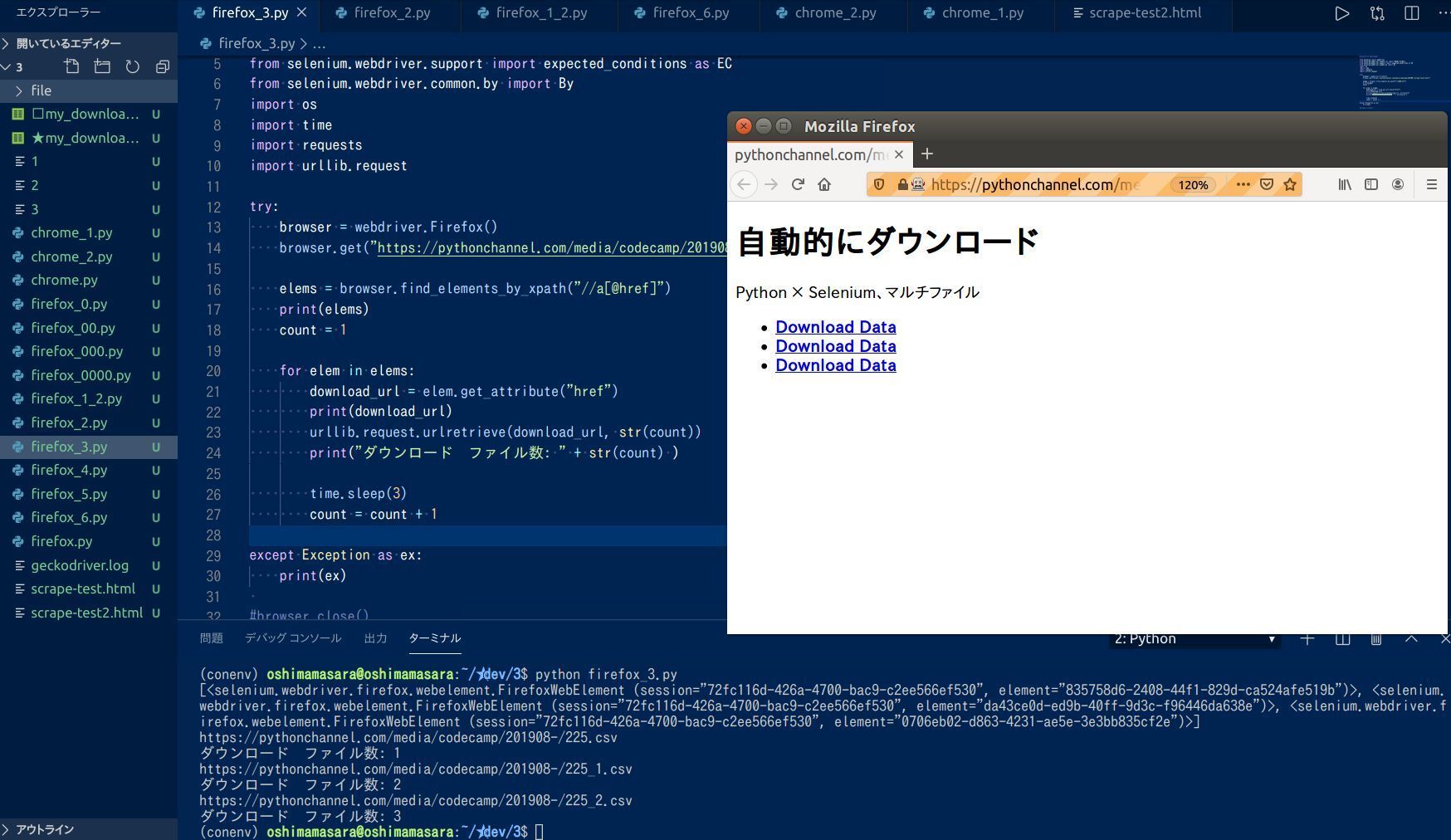
elems = browser.find_elements_by_xpath("//a[@href]")
print(elems)
count = 1
for elem in elems:
download_url = elem.get_attribute("href")
print(download_url)
urllib.request.urlretrieve(download_url, str(count))
print("ダウンロード ファイル数: " + str(count) )
time.sleep(3)
count = count + 1
except Exception as ex:
print(ex)
複数のファイルを Webページから一度にダウンロードしようと思うと、ダウンロード対象の URL をどう集めるか、という点が重要になってきます。今回は Selenium の find_elements_by_xpath(//a[@href]) を使って a タグの href を収集。 今は a タグですが、画像をダウンロードしたい時は find_elements_by_xpath(//img[@src]) とすれば OK。
そして Webページから収集した aタグの href は、 変数: elems に格納。今回のサンプルページ では aタグが 3つなので、 elems の中に 3つ Selenium オブジェクトが入っていることが確認できます(上図参照)。
そして 3つの Selenium オブジェクトをループ文で順番に処理。 elem.get_attribute("href") とすることで、 URL の値をもつ Seleniumオブジェクトを文字列に変換、そしてその URL を urllib.request.urlretrieve(〇〇、 △△) することで URL のファイルをダウンロード。 Webページ上の aタグすべての URL にアクセスして、 CSV や pdf ファイルがダウンロードされることになるでしょう。
Chrome についても 13行目の
browser = webdriver.Firefox()
を
browser = webdriver.Chrome()
に変えるだけで OK。 こうしてみると URL からファイルをダウンロードする方が、ブラウザ毎の仕様を気にしなくていいので便利。それでは最後に Yahoo Finance に公開されている株価や為替、仮想通貨などの価格情報をダウンロードしてみましょう。
ファイル拡張子のないファイルをスクレイピングでダウンロード
Yahoo Finance にアクセスして "Historical Data" のメニュータブを選択すると過去の株価などを確認する事ができます。そして "Download Data" の文字をクリックすると設定した範囲のデータを CSV ファイル でダウンロードできるのですが、 このダウンロードの URL がちょっと特殊です。

上記画像の Download URL/ https://query1.finance.yahoo.com/v7/finance/download/4151.T?period1=1544063567&period2=1575599567&interval=1d&events=history&crumb=qz8v.h2aQqI
試しに FireFox と Chrome で URL からファイルをダウンロードするパターンを試してみました。しかし結果は ❌。

FireFox で 拡張子のないファイルをダウンロードしようとした結果
上図のURL
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import os
import time
import urllib.request
try:
browser = webdriver.Firefox()
browser.get("https://finance.yahoo.com/quote/4151.T/history?period1=946652400&period2=1575558000&interval=1d&filter=history&frequency=1d")
elem = browser.find_elements_by_xpath("/html/body/div[1]/div/div/div[1]/div/div[3]/div[1]/div/div[2]/section/div[1]/div[2]/span[2]/a")
# 同じURL でもボットがアクセスすると XPATH が変わる /html/body/div[1]/div/div/div[1]/div/div[3]/div[1]/div/div[2]/div/div/section/div[1]/div[2]/span[2]/a
print(elem)
download_url = elem[0].get_attribute("href")
print("URL:: " + download_url)
urllib.request.urlretrieve(download_url, "\\_YahooFinance.csv")
time.sleep(3)
except Exception as ex:
print(ex)

Google Chrome で拡張子のないファイルをダウンロードしようとした結果
上図のURL
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import os
import time
import urllib.request
try:
browser = webdriver.Chrome()
browser.get("https://finance.yahoo.com/quote/4151.T/history?period1=946652400&period2=1575558000&interval=1d&filter=history&frequency=1d")
elem = browser.find_elements_by_xpath('//*[@id="Col1-1-HistoricalDataTable-Proxy"]/section/div[1]/div[2]/span[2]/a')
print(elem)
download_url = elem[0].get_attribute("href")
print("URL:: " + download_url)
urllib.request.urlretrieve(download_url, "\\_YahooFinance.csv")
time.sleep(3)
except Exception as ex:
print(ex)
FireFox の方は URL すら取れていない感じですが、 Google Chrome の方は URL は取得できています。今まで同じように URL を取得できてきた FireFox と Chrome 、今回は ❌ でした。 FireFox の方が ❌ な原因は、 Webページを読み込んだ際に Bot と 自分のパソコンでは同じ URL でも HTML の構造が違うということ。試しに "Download Data" の XPath をボット側でも取得してみましたが以下のように異なる結果になりました。
【自分のパソコンから取得した XPath】
/html/body/div[1]/div/div/div[1]/div/div[3]/div[1]/div/div[2]/section/div[1]/div[2]/span[2]/a
【ボットのWebページから取得した XPath】
/html/body/div[1]/div/div/div[1]/div/div[3]/div[1]/div/div[2]/div/div/section/div[1]/div[2]/span[2]/a
上図の FireFox のプログラム内の XPath をボット側のコードに変えると、 URL は取得することができました。しかし、 urllib.request.urlretrieve(〇〇, △△) でアクセスしても 401 error。これは Yahoo Finance の Webページでキャッシュが働いているため。 "Download Data" の URL を他のブラウザでアクセスしても ❌ ですが、ボットのブラウザでアクセスすると OK という特殊な構造となっています(下図参照)。

スクレイピング取得した URL にアクセスした結果。 左:自分のパソコンのChrome、 右:ボット。 ボットの方は、ファイルのダウンロードに成功しています。
この問題、恐らくブラウザは Selenium の browser = webdriver.Firefox() や browser = webdriver.Chrome() で開いているのに対して、 URL のアクセスは Selenium ではない urllib.request.urlretrieve(〇〇, △△) で開いているために起きていると推測。
改めて click() を使って処理を実行してみます。

上図のURL
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import os
import time
import urllib.request
try:
browser = webdriver.Chrome()
browser.get("https://finance.yahoo.com/quote/4151.T/history?period1=946652400&period2=1575558000&interval=1d&filter=history&frequency=1d")
download_button = WebDriverWait(browser, 5).until(EC.element_to_be_clickable((By.XPATH, '//*[@id="Col1-1-HistoricalDataTable-Proxy"]/section/div[1]/div[2]/span[2]/a')))
download_button.click()
time.sleep(3)
except Exception as ex:
print(ex)
実際に上記のプログラムを実行してみると時間は少しかかりますが、無事に拡張子のないファイルをダウンロードできました。 FireFox については XPath の構造が変わるためにパス。またダウンロード先は Chrome の設定を変更していないので、デフォルトの "ダウンロード・フォルダ" に入っていきますね。
ここまで色々説明してきたにもかかわらず、最初に戻った感じが... あとはアクセスする Webページの URL の部分を 違う証券コードに変えれば Yahoo Finance からたくさんの銘柄のファイルをダウンロードすることができるでしょう。
225個のファイルを自動でWebページからダウンロードする方法

上図のURL
from selenium import webdriver
import os
import time
import csv
import pandas as pd
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
csvfile = "225.csv"
def get_csv():
count = 1
with open(csvfile, "r") as f:
rows = csv.reader(f)
for row in rows:
print("Yahoo Finance アクセス回数: " + str(count))
row_str = str("".join(row))
url = "https://finance.yahoo.com/quote/" + row_str + ".T/history?period1=946652400&period2=1575385200&interval=1d&filter=history&frequency=1d"
driver.get(url)
time.sleep(5)
page = driver.find_element_by_tag_name("html")
try:
download_button = WebDriverWait(driver, 5).until(EC.element_to_be_clickable((By.XPATH, '//*[@id="Col1-1-HistoricalDataTable-Proxy"]/section/div[1]/div[2]/span[2]/a')))
download_button.click()
time.sleep(3)
count = count + 1
time.sleep(1)
except:
print("try error:: データ取得できず....")
with open("225Price.csv", "a") as csvFile:
writer = csv.writer(csvFile)
writer.writerow([row_str, "エラー"])
csvFile.close()
count = count + 1
time.sleep(1)
def create_225data():
count = 1
with open(csvfile, "r") as f:
rows = csv.reader(f)
for row in rows:
print("225銘柄読み込み中... ループ回数: " + str(count))
row_str = str("".join(row))
stock_csvfile = open(row_str + ".T.csv")
df = pd.read_csv(stock_csvfile)
old_date = df.iloc[0][0]
new_date = df.iloc[-1][0]
old_price = df.iloc[0][4]
new_price = df.iloc[-1][4]
with open("my225.csv", "a") as csvFile:
writer = csv.writer(csvFile)
writer.writerow([row_str, old_date, old_price, new_date, new_price])
count = count + 1
time.sleep(1)
print("--- START ---")
get_csv()
create_225data()
print("--- FINISH ---")
ここまでのスクレイピング・テクニックと Python の CSV 操作を応用して、 日経225 の 225銘柄分の価格データを順次ダウンロードするプログラムを作成してみました。一つ一つのファイルをダウンロードするのに少し時間はかかりますが、自動でファイルをダウンロードしてくれるので便利。
また合わせて過去の株価と直近の株価だけを 225銘柄分新しい CSV に保存。必要であればダウンロードファイルから計算を行い、その結果も自動で記録することができるでしょう。
今回ご紹介したコード: GitHub/oshimamasara
上記プログラム実行後、データ整理をする中で、取得したファイル内に著しく本来の株価と乖離するモノがいくつかありました。データ収集の難しさを痛感させられます。 API などを利用して JSON形式でデータ取得する方が賢明かもしれません。
\AIエンジニアに必要なスキルが身に付く/
まとめ
今回 Webページからファイルをダウンロードする方法をご紹介させて頂きましたが、意外とケースバイケースで上手くいったり上手くいかなかったりすることが分かりました。
恐らくプログラミング学習も同じで、教科書通りにやってるはずなのに上手くいったり、上手くいかなかったり...という時もあるでしょう。こうした問題が発生した時、高いモチベーションと体力、時間があれば問題を解決できると思いますが、いつもそうとは限りません。中にはプログラミング学習をやめてしまうケースも...
一呼吸おいて考えましょう。自分はプログラミング学習を辞めたとしても、社会は IT の進化を止めません。厳しいかもしれませんが、高度な情報化社会においていかれる可能性も ゼロ ではないでしょう。
「困ったな...」「なんとかプログラミングスキルを身につけたいな...」 そんな思いに直面した時、プログラミングスクールが大きな助けになることも。 お金と勇気は必要かもしれませんが、将来への不安が解消されるとしたらどうでしょうか?
CodeCamp では 無料体験レッスン を通じて、"プログラミングスクールに通う価値" を確かめられます。悩んでいるだけでは何も前に進みません。まずは無料体験で初めの一歩を踏み出しましょう!
詳しくは 公式ページ より確認してみてください。
昨今のプログラミング・ニーズの高まりを受けて、無料体験枠が埋まっている日もあります。予め、ご了承ください。







- この記事を書いた人
- オシママサラ







