- 更新日: 2020年01月09日
- 公開日: 2019年12月27日
囲碁界最強のアルゴリズムAlphaGoを使ってみよう

2017年Google社が開発した人工知能 AlphaGo は、囲碁レベル世界 1位のイ・セドルを破ったことで有名に。その囲碁界最強ともいわれるアルゴリズム AlphaGo、実は私達もプログラムを動かしたり、編集したりすることができるってご存知でしたか?
Pythonの基本スキルさえあれば誰でも AlphaGo 実行できますので、その手順をご紹介したいと思います。
実際に動かすアルゴリズムは AlphaGo 後継モデルの AlphaZeroになります。
本稿ではストレス負荷の観点から、 AlphaGo の統一表記。
また囲碁は演算負荷が大きいことから、 Conect4 というゲームで AlphaGo アルゴリズムを実行していきます。
囲碁界最強のアルゴリズムAlphaGoを使ってみよう
AlphaGoとは

img : The Principles Of A.I Alphago / YinChen Wu, Dr. Hubert Bray / Duke Summer Session / 20 july 2017
AlphaGoは、 2014年に DeepMind が「囲碁ゲームにおいて、ニューラルネットワークがどれぐらいうまく動くのか」 ということを検証するためにスタートしたプロジェクト。当時は IBM のディープブルーがチェス世界一を破ったりして、人工知能が注目され始めていた時代。Googleも力を試してみたかったのでしょう。
AlphaGo自体は、ソフトやライブラリなどではなく、一つの「設計モデル」です。囲碁という限られた範囲、決まったルールのもと、どうすれば強くなるのか、という課題に対して結果を出すように作られたプログラム群。つまり AlphaGo 自体には、汎用性はなく、囲碁に限ったプログラム。ただ碁盤をオセロに変えたり、コマを将棋やチェスに変えると応用できるという訳。
今回 AlphaGo を使って Connect4 を実行しますが、正確には「AlphaGoモデルを参考にした Connect4」となります。
尚、AlphaGoモデル の特徴としては、
- 訓練データ無し
- 自己完結型
- ルールのみ設定
- 訓練に時間と演算パワーが必要
人工知能や機械学習について少し知識がある方ならお気づきになると思いますが、 AlphaGoモデルは ”訓練データなし” で学習していきます。つまり前例のないようなゲームでも、自分で学習を積み重ねて、どのパターンで勝てるかを学習していきます。
学習アルゴリズムには、 ニューラルネットワークとモンテカルロツリー(モンテカルロ木探索)を使用。モンテカルロツリーで次の一手のパターンを形成し、パターンの分だけ実行、そしてその結果をフィードバックし、検証。そのパターンの中でよかった ”一手” に重みを置き、ニューラルネットでその ”一手” のスゴさを検証し、内容を記録。 こうしたアルゴリズム処理を繰り返すことで「その場合なら次の一手はここが一番重みがある、いける!」となって強くなる、という訳です。
人間も同じような思考で、囲碁や将棋、オセロをプレイすると思います。しかし、人間の場合はすべての ”手” を打って、その結果を検証することは大変時間がかかりますし、内容を覚えきれません。しかし、プログラムならメモリーに今までの検証記録を保持させ、現在の状況に合わせた最適な一手を算出することができる、ということです。
既に計算速度では人間、コンピューターに勝てませんが、囲碁のようなパターン分析やゲーミングの分野でもコンピューターに負けようとしています。チョット前までは、コンピューティング能力が低かったので、 AlphaGo のようなアルゴリズムが登場しても実用化には時間がかかったのですが、今は CPU 以外に演算を得意とする TPU も GPU もあり、難易度の高い演算処理もこなせるような環境が。しかもこうしたハイスペックなコンピューティング、個人でも一時的になら無料で利用することができます。
【個人でも無料で利用できる GPU と TPU 環境】
Google Colaboratory (TPU、 GPU)
Kaggle (GPU)
つまり
AlphaGoレベルの思考回路・演算処理を誰でも無料で使える
ちょっとヤバくないですか、 世界最強レベルの囲碁アルゴリズムを誰でも使える環境。囲碁は 19×19 ですが、これをビジネスやトレーディングに応用できると考えたら...
実際には、 AlphaGo の場合、決まったルールの元、自己完結型で他の要素を取り入れない条件でプログラム処理を進めますので、現実社会への応用というのは難しい。しかし、少なくとも囲碁や将棋、オセロなどのゲームにおいては自分でも最強ゲーマーを作ることができそうという訳です、ただし必要な演算パワーがあればですが...
前置きが長くなりましたが、実際に AlphaGoモデル を動かしていきたいと思います。
AlphaGoモデルを動かす環境
いつもの自分のパソコンで大丈夫です。

- パソコン: インターネットにつながれば何でもOK
- ブラウザ: Google Chrome推奨(Googleアカウント要)
- 実行環境: Google Colaboratory(Webサービス)
- ゲーム内容: Connect4
- 参考にしたコード: GitHub/ DeepReinforcementLearning
普通自分のパソコンでニューラルネットなどのディープラーニングを行うと、 PCパワーがマックスになり、音と熱、スゴイと思います。また最先端の CPU や GPU などに比べると非力がち。そのため「まだ終わらないのかな...」と眠気に誘われることもよくあると思います。
この問題、 Google の Colaboratory や Kaggle などのクラウド・マシーンを使うと解決。両者とも無料で使えるサービスで、クラウド上でプログラムを実行しますので、音や熱、通信速度にパケット量、ほとんど気にしなくて OK です。そして作成したクラウド上の実行環境も、消したり、新しく作ったり、ローカル環境に比べると安心して挑戦できます。ただし、利用時間は 6時間など制限されていますので要注意。
今回 AlphaGo のアルゴリズムを使って挑戦するゲーム ”Connect4” は、コインを 早く4つ並べた方が勝ちのゲーム。
【Connect4の様子】
動画では 5×6 ですが、今回は 縦 6 横 7 の合計 42マスあるボードを使用し、コインを交互に入れて、勝てるパターンを学習。 5目並べと違って、コインは上から入れて下詰めになるという特徴があるため、入力のパターンは横マスの数と同じ 7通り。次の”一手”のパターンが 7通りに絞られるため、オセロや囲碁に比べると比較的演算負荷は少なくて済むと思います。
しかし、たった 42マスしかない Connect4 ですが、なんとコインの配置パターンは 4,531,985,219,092通り、スゴイですね。人間にはこの配置パターンとても覚えられませんが、コンピューターなら可能というわけです。
参考プログラムについては、イギリスの AI・データサイエンス企業 Applied社のものを利用させて頂きました(ライセンス: GPL-3.0)。オセロやチェス、五目並べ など AlphaGo を使ったサンプルはありますが、こちらのプログラムが一番実行しやすく、分かりやすかったです。
AlphaGoを自分のパソコンから実行する様子
本テキストと合わせてご参照下さい。
AlphaGoを自分のパソコンから実行(準備編)
今回は Jupyter Notebook のコードに従って手順を進めていきたいと思いますので、まずはベースとなる run.ipynb を用意します。 run.ipynb は GitHub から直接 Google Colaboratoryにダウンロード、インストールしてもいいでしょうし、一旦内容を確認してからでもOK。
Google Colaboratoryで利用しやすいようにプログラム編集したものは、以下のファイルになります。
run.ipynb(Google Colaboratory用)
run.ipynb が準備出来たら、 Google Colaboratoryに run.ipynb をセット。

Google Colaboratoryの上部メニューバーから「ファイル → ノートブックを開く」を選択。先ほどの run.ipynb を選択すると自動的にコードがブラウザ上にセットされます。

次は、プログラムの実行環境を TPU にセットしておきましょう。上部メニューバーから「ランタイム」内の「ランタイムのタイプを変更」から TPU に変更できます。

画像クリックで拡大
そしてこのノートブックに従ってプログラムを実行していくわけですが、まずは必要なプログラム群を現在の実行環境 Google Colaboratory にセットする必要があって、これは GitHub からクローンします。
GitHub でプログラムを管理するメリットは、
- 12時間経って Google Colaboratory のマシーンがリセットされても、プログラムファイルを GitHub 上で管理・保存できる
- ちょっとしたプログラムの編集なら ブラウザ上でできる
- 一度 Google Colaboratory にセットしたプログラムファイルは編集しにくい
一番最初の !git clone https://github.com/oshimamasara/DeepReinforcementLearning.git を実行することでファイル群をインポート。ちなみにこのインポートするファイルは、 Google Colaboratory 用にファイルパスなどを編集しています。
【オリジナルから編集したファイル】
config.py / ニューラルネットなどの学習設定が初期値のままだと中々進まないので、大幅に省略化
model.py / ファイルのパスを変更
settings.py / ファイルのパスを変更
オリジナルのファイル郡 / https://github.com/AppliedDataSciencePartners/DeepReinforcementLearning.git
今回使用するファイル郡 / https://github.com/oshimamasara/DeepReinforcementLearning.git
ファイル群のインポートに成功したら、次は必要な pip のインストール。 requirements.txt に必要な pip 記載されていますので、 Jupyter Notebook 内で pip を取り込んでいきます。下記コマンドで Jupyter Notebook からでも pip install することが可能。

画像クリックで拡大
!pip install -r DeepReinforcementLearning/requirements.txt
pip install ・・・・・ の実行中、途中エラーが出ると思います。
一旦プログラムの実行が終わるまで待って、output のセル一番下に書かれている 「Restart」 ボタンをクリック(下図参照)。

画像クリックで拡大
Jupyter Notebook が読み込み直されたら、もう一度
!pip install -r DeepReinforcementLearning/requirements.txt を実行

画像クリックで拡大
今度はエラーが出てこないと思います。
次は、必要なクラスやモジュールを読み込むために、作業ディレクトリを DeepReinforcementLearning 内に移動します。 %cd DeepReinforcementLearning で Jupyter Notebook からでも作業ディレクトリを移動できますね。
移動できたかどうかの確認は !ls か !pws で確認できるでしょう。
AlphaGoを自分のパソコンから実行(実行編)

画像クリックで拡大
プロジェクト実行に必要なファイル群と pip が準備出来たら、プログラムの実行です。まずは必要なライブラリ、クラスなどを import。 この時のポイントとしては、 pip のライブラリの他に本プロジェクト内の Pythonファイルも読み込まれているということ。 game、 agent、 memory など。このあとのプログラム処理を理解しようと思うと、各 Python ファイルを熟読しておく必要が。
各ファイルの要約
game.py / Connect4 のゲームルールがプログラム、今回は 7×6 の 42マス。
agent.py / プレーヤーの動きをセットしたファイル。モンテカルロサーチツリーの検索プロセスや実行後の評価(ニューラルネット)、過去の記録を使っての再トレーニングなど盛りだくさんの内容。
memory.py / 再トレーニングに必要な過去のデータを記録
model.py / Keras を使った残差畳み込みネットワークのアルゴリズム処理が記述。ニューラルネットワークの実行部分。
funcs.py / プレイヤー1とプレイヤー2の対戦処理を行うプログラム。
config.py / ニューラルネットワーク処理に関するパラメータを設定するファイル。セルフトレーニング、再トレーニング、評価の 3項目。オリジナルのまま実行すると、ものすごく時間がかかります。
MCTS.py / モンテカルロサーチツリーに関するプログラム
loggers.py / セルフトレーニングの様子を記録するために log ファイルに保存するためのコード
loss.py / セルフトレーニング検証用のプログラムで、ニューラルネットで重みを設定したところに打ったかどうかの評価値です。数値が低いほど、プログラム処理が ニューラルネットワークに従っていると考えられます。
settings.py / 保存や読み込みのファイルパス。今回は Google Colaboratory用に設定しています。
util.py / log ファイルに関する設定コード

画像クリックで拡大
エラー無く import 処理できたら、次はいよいよ本命プログラムの実行です。 123行からなる本命プログラムをすべてご紹介することはできませんが、まずは大まかにプログラムの流れを把握する必要があるでしょう。 54行目: while でループ処理、 72行目: if len(memory.ltmemory) >= config.MEMORY_SIZE: で条件分岐など(上図参照)。
そしてこのプログラムで一番重要なポイントは、なんでしょう。そうです強い思考を持った訓練済みのデータを取得することです。機械学習やディープラーニングなどではよく .pkl というファイルが学習済みデータとして出力されて、利用されます。今回のケースでは .pkl ではなく .h5 という階層型のデータ(Hierarchical Data Format)。

今回出力された version0005.h5 の中身
117行目: if scores['current_player'] > scores['best_player'] * config.SCORING_THRESHOLD: によって前のユーザーより強くなった場合、そのモデルは .h5 化されて run/models フォルダ内に保存。
上記プログラムを実行している限り、 〇〇.h5 が出力されたり、 logs フォルダ内に各種ログ情報が追加されていきます(下図参照)。

画像クリックで拡大
このプログラム、終わりはあるかな、と思い半日程ずっと実行していましたが、終わりはありませんでした。時折出力されるグラフの損失係数が下がってきたら、ニューラルネットに従ってアルゴリズム処理されていると判定できますので、プログラムを止めてもいいかもしれません。ちなみに本コードの参考ページでは、数日間プログラムを実行し続けた結果、以下のようにニューラルネットの指示を聞くようになったようです(下図参照)。
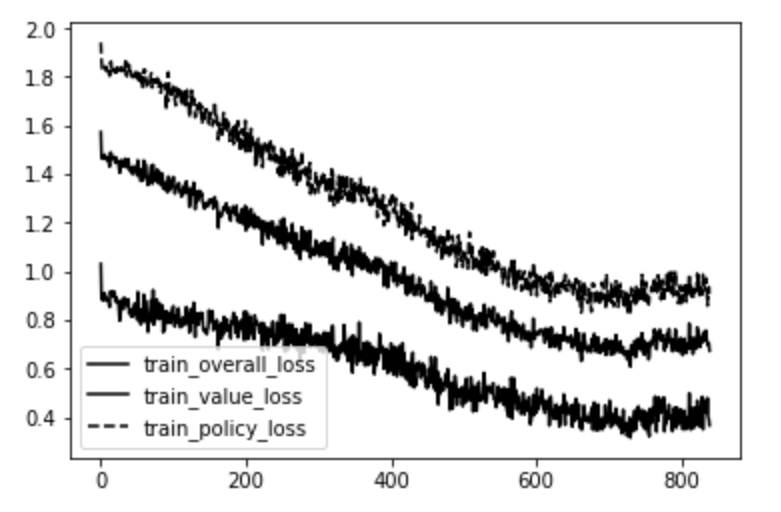 img: APPLID
img: APPLID
Google ColaboratoryとGoogle Driveを接続してデータ保存
上記ニューラルネットとモンテカルロサーチツリーのプログラムを実行後、作成できた memory や log、 model ファイル(version0005.h5)などを保存したい時、ありますよね。普通 Jupyter Notebookでは、ファイルやフォルダをローカルにダウンロードできる機能がありますが、 Google Colaboratoryにはダウンロード機能がありません。現在作業している .ipynb ファイルのみダウンロードできます。
ちょっと不便に感じるかもしれませんが、 Google Drive を使うとデータ保存やデータ読み込みのストレスが軽減されます。

画像クリックで拡大
まずは現在動かしている Google Colaboratoryマシーンと Google Drive を接続。 Colaboratory 画面左のサイドバー内「ファイル」にある ”ドライブをマウント” をクリック。するとセルにコードが自動追加されます。そしてそのコードを実行。すると今度は URL が表示。その表示された URL を開いて、 Googleアカウントにログイン。すると キー が表示されますので、キーをコピーして Colaboratory のセルに表示されている入力枠にキーコードを貼付け。そしてリターンキーを押し、 1分ほど待つと接続が完了。

画像クリックで拡大
左サイドバーを更新し、 drive というフォルダが出てきたことを確認します。念の為、中身もチェックしておきましょう。そして現在の作業ディレクトリを確認し(上図参照)、 %cp -r run ../drive/My\ Drive/〇〇 を実行。すると Colaboratory にある run フォルダが自分の Google Drive 内に貼り付けられます。
画像クリックで拡大
逆に Google Drive 内のデータを Google Colaboratoryに取り込みたい場合は、 %cp -r drive/My\ Drive/2019/run DeepReinforcementLearning を実行。フォルダ名やディレクトリ名などは適当なものに変更してご利用下さい。
プログラムの実行時間にもよりますが、 2時間程度プログラムを実行した run フォルダは、圧縮データで 60MB ほどになります。ローカル環境に runフォルダ 60MB をダウンロードするとパケット量の負担に。しかし、今回は Google Colaboratory も Google Drive も両方クラウド上での処理のため、パケットはほとんど関係ない状態。かなり早いネットワークで処理してくれます。
AlphaGoモデルの動いている様子

画像クリックで拡大
動いている、と言いましても LIVE ではなく log の履歴になります。上図のように log を確認すると、今回作成した AlphaGoモデルがどんな動きで Connect4 をプレイしているのか分かります。”予測”のところの数字がニューラルネットワークによって変動していき、 ❌ と ○ が交互に自動的に配置されていた様子が確認できますね。
”予測”の数字が大きいにも関わらず、違うところにコインを配置したケースは損失ケースになって、グラフの値を上げるでしょう。コインを順番に積んでいき、勝つとゲームがリセットされて、またセルフプレイが始まります(下図参照)。

画像クリックで拡大
今度はこの勝ったゲームの伝播(思考)を modelフォルダに version0001.h5 として保存し、次のゲームの行動指針となります。そして繰り返しセルフプレイして、自分自身が戦い合って強くなる、ということになります。その産物として、 model の version0009.h5 などの学習済みデータを取得。
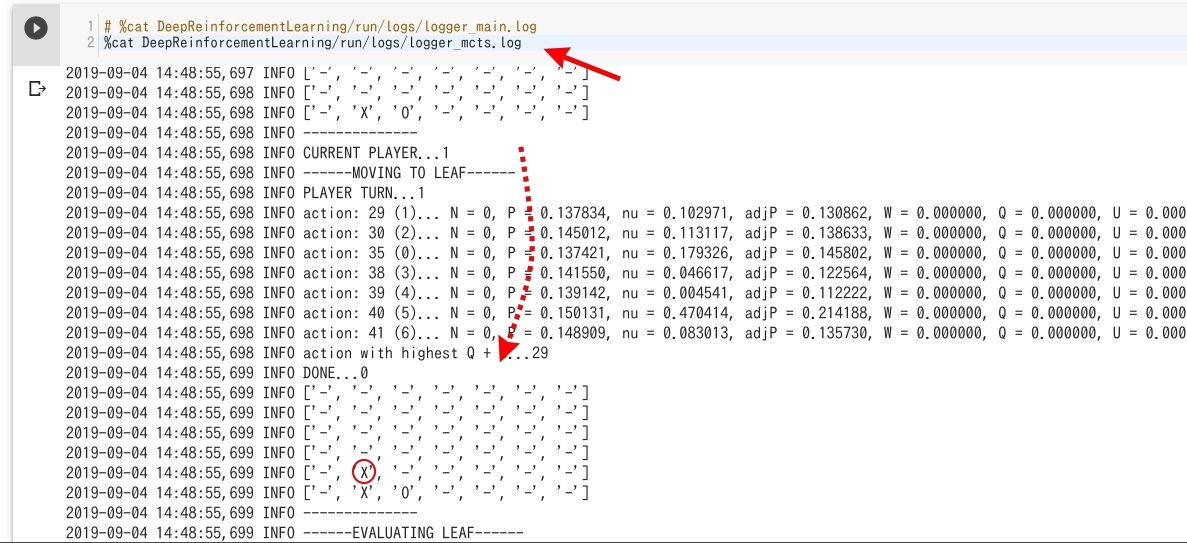
画像クリックで拡大
ほかにもモンテカルロサーチツリーの動いている様子(logger_mcts.log)なども、おもしろいと思います(上図参照)。いろいろ %cat 〇〇 でファイルの中身をチェックしてみて下さい。

画像クリックで拡大
それからニューラルネットワークのプログラム(123行)を実行した時に生成された model.png もユニークなデータです。今回 model.py や config.py などでセットしたニューラルネットワークの様子を図で確認することができます。内容はちょっと難しいのですが、人間にはチョット理解しがたい難しいことも、コンピューターなら簡単にこなせることが分かりますね。
セルフトレーニングした成果(検証)

画像クリックで拡大
さて今回の AlphaGo モデルを参考にしたプログラム、どれだけ強くなったでしょうか?下記コードで検証できます。
playMatchesBetweenVersions(env, 1, 0, 7, 10, lg.logger_tourney, 0)
playMatchesBetweenVersions(実行バージョン, プレーヤー1のバージョン番号, プレーヤー2のバージョン番号, ゲーム数, ログイン先, 先手(0はランダム))
上記のバトルコードでは、プレーヤー1 に初期状態の学習なしのプレーヤーを設定、プレーヤー2 に model/version0007.h5 のバージョンをセット。結果はなんと、学習していないプレーヤー1 の方が強いという結果に。学習が全然できていなく、 config.py のパラメーターも適当に変更していることが影響しているのでしょうか...
今回の設定は AlphaGoモデル を体験することを優先したためこのような結果になりましたが、参考元のチュートリアルでは学習毎に強くなっている様子が確認できます(下図参照)。

img: APPLIED
数日間のトレーニングの成果のようです。
また上記バトルコードのプレーヤー1のバージョンを -1 にすると、 自分 対 学習済みコンピューターで対戦できます。

ただ、ここに何の数字を入れればいいか、プログラムが解読できていません。解決時間なく、申し訳ないです。
仮に入力方法が分かったら、 AlphaGo Connect4 世界最強モデル VS 自分 で対決できるかもですね。 iOS や Android のアプリで UI セットし、プレイできたらおもしろそうですね。また今回は Connect4 を AlphaGoモデルで実行しましたが、他にも AlphaGoモデルを使っているサンプルや AlphaGoのテキストがあります。お時間ある時にご参照下さい。
AlphaGoをベースにしたサンプルまとめ
- AlphaGo の論文(ネイチャー)
- スタンフォード大学のテキスト
- AlphaGoのミニ版(TensorFlowチーム)
- 今回のConect4(Applied社)
- 五目並べ(MIT)
- オセロ(MIT)
- チェス
(補足)今回の実行環境がGoogle Colaboratoryな理由
今回の AlphaGoモデル 実行にあたっては、
- ローカル環境
- クラウド型IDE(クラウド型開発環境)
- クラウド型Jupyter Notebook
という風にいくつかの実行環境が考えられます。それぞれに AlphaGo モデルのプログラムをセットして、試してみました。
まずローカル環境については、 requirements.txt に記載されている pip をインストールできませんでした。私の時は何かのライブラリのバージョンエラーと表示され、いろいろ対応したものの ❌。 ローカル環境では GPU もないので、実行できたとしても非力かな?とも思っていました。
次にクラウド型IDE。こちらは Paiza Cloud や GitPod でテスト。しかし、ローカル環境同様に requirements.txt を実行するとエラー。少し頑張りましたが、結局解決できませんでした。
そして最後に TRY したクラウド型の Jupyter Notebook。 Google Colaboratory以外テストしていませんが、 requirements.txt もスムーズ時に実行でき、 ハイスペックな TPU や GPU もあるのでこちらで AlphaGo を動かすことに。
\AIエンジニアに必要なスキルが身に付く/
まとめ
1週間ほど前に AIに自分の仕事を食われている、と気づいた私:大島ですが、今回の AlphaGoモデル を操作していると、「AIで食えそう」な気がしてきました。 AI に対するマインドが反転したのです。
1週間前は「やべえな、この先どうなるかな...」という心境だったのが、「なるほど、自分でもこんなことができるのか、 Google や Amazon などのプラットフォーマーもいろいろ考えてくれているんだな。 AI 時代に向けた準備環境はあるので、あとは個人のやる気次第か」という思いに。そして 「もっと Python 使いたいな、学びたいな」 という心境。
AIによって今より仕事は減る、といわれ AI社会に対応した一部の人だけが仕事にありつけると言われています。今ピラミッド社会の上を目指している人、競合他社の上を目指しいてる企業、何をすればいいか答えは出ていますね、 AI対応ですね。
AI順応者(社)が生き残ると言われているのなら、生き残れば必然的にピラミッド社会の上層に。あれこれ思案する間に AI、 AIリテラシーの向上を目指す方が、手っ取り早いかもしれませんね。
オンラインのマンツーマンレッスンで定評のある CodeCamp では、 AI や データサイエンスに興味がある方向けの Pythonデータサイエンスコース を運営中。また AI に限らず IT 全般、特に Web についてもっと基礎から知りたいという方は テクノロジーリテラシー 速習コース という科目があります。
「自分にはどのコースがいいのかな?」「仕事が忙しいけど続けられるかな?」といろいろ不安に思っている皆様、一度 ”無料体験” を検討してみませんか? マンツーマンで講師の方とレッスンでき、実際に簡単なコードも書いて、動かしますよ。
「無料体験」は随時受け付けていますので、詳しくは 公式ページ より確認してみてください。







- この記事を書いた人
- オシママサラ








