- 更新日: 2020年07月10日
- 公開日: 2020年03月19日
PythonでGoogle Photoを50GBの無料サーバーにバックアップ

Google Photo の "無制限ストレージ容量"、私達ユーザーにとって魅力的ですよね。
私は今まで 年間 2,500円で 100GB のストレージを借りていましたが、思い切って Google Photo を無料プラン(高画質モード)に変更してみることに。
すると...「あれっ、結構画像サイズ圧縮されていない? 16Mピクセルまで OK だったのでは...」 という、まさかの事態が発生...
そして頭の中で「あぁ、バックアップとっとけばよかった....」と後悔。
そんな訳で今回は Google Photo のバックアップを、 50GB 無料ストレージをもつ Oracle クラウドに保存する方法をご紹介します。
1つの Oracleコンピューターでは MAX 50GB ですが、 Oracleクラウドは 2つまで無料コンピューターを利用できますので、最大保存容量は約 100GB、お得ですよね。
【今回のバックアップ方法】
・ Google Photo API を使ってデータ通信
・ Oracle Always Free を使って、 ディスク容量: 50GB のコンピューターに保存
・ FTPソフトでバックアップファイルを管理
バックアップも管理費もすべて無料!
PythonでGoogle Photoを50GBの無料サーバーにバックアップ
詳しい手順をご紹介する前に、まずは結果から。

FTPソフトで Oracleクラウドに接続し、 Google Photo のバックアップを確認する様子
今回は、Oracleクラウド上に Google Photo のデータを保存しますので、基本コマンド操作、もしくは FTPソフトを利用してのファイル操作になります。 普段コマンドを使わない方にとっては使いにくいかもしれませんが、「プログラミング学習」 ということでご了承下さい。
Google Photoのデータをバックアップする理由

Google Photo のプランを "元のサイズ" から "高画質" に変更した後のストレージ消費量、一見するとお得そうですが...
画像共有や動画共有、それから保存にバックアップ、いろいろ使い勝手のいい "Google Photo" のデータを "なぜ" バックアップするか、まずは理由を確認します。
- 利用プランを "元のサイズ" から "高画質" に変えた際発生する 「データ圧縮」 の回避策として
- 利用プラン "元のサイズ" を利用されている場合の "Google One" スペース節約のため

Google Photo のヘルプを確認すると、画像は 16Mピクセル、動画は 1080p まではサイズ変更されない、と読める説明書きがあります(Google Photo ヘルプ)。しかし、実際に Google Photo のプラン(設定) を "元のサイズ" から "高画質" に変更すると、下図の様に結構な割合でデータ圧縮が実行。

一般的にデータサイズを圧縮すると画像が荒くなるイメージがありますが、 Google の画像圧縮技術はスゴイのか、ほとんど画像の粗さを感じません。 見た目的には変化がないのでバックアップ不要とも思えますが、データサイズが著しく変わっている以上、バックアップを取っておく方が安心ですよね。
ちなみに Google Photo のバックアップは、 Google Takeout から利用可能。しかし、 10GB などのデータを自分のパソコンにダウンロードするのは気が引けます。またダウンロード後のデータ管理も不安。
そんな "不安" を Google Photo API を使って Oracle クラウドに保存できれば、 パケット量もパソコンの空きスペースも気にすることなくバックアップできます。こうしたことを踏まえて、今回のバックアップ環境を考えました。
現状 Oracleクラウドは、 Alway Free ということで期限無しで無料コンピューターを利用できますが、 Java SE のように Oracle サイドの事情で規約が変わる可能性もあります。サポートメールなど無視することなく、気にしておきましょう。
今回の作業環境

- プログラミング言語: Python
- プログラム開発: Google Colaboratory
- Google Photo Data: Google Cloud Platform
- 保存先: Oracle Cloud(無料プラン)
- バックアップ時間: 約 30分(ファイル数 約3300)
今回は Google Photo のデータを "Google Photo Library API" を使ってダウンロードしていきます。自分でクリックすることなく、 プログラムが自動処理。
プログラム処理に Python を使用しますが、自分のパソコンに Python がセットされていなくても大丈夫。オンライン上で Python を利用できる Google Colaboratory を使用します。 Google のアカウントがあれば直ぐに Python 実行可能。
それではまず Google Photo API に接続する所からはじめ、自分の Google Photoデータをチェックする方法、全ファイルをクロールする方法、ダウンロードする方法などいくつかのステップを踏んで、最終的に全ファイルのバックアップを実行したいと思います。
Google Photo API用のOAuthを取得する方法
OAuth とは、 "権限の認可" という意味で、 自分の Google Photo へのアクセスを実行するために必要なプロセス。今回は自分のデータにアクセスする、という内容なので必要最低限の設定で OAuth を設定します。

https://cloud.google.com にアクセスして、 画面右上の 「コンソール」 をクリック。

今回 Google Photo API を利用するための "プロジェクト" を作成。画面中央上部の project名をクリックし、 「NEW PROJECT」 で新規プロジェクト作成の手続きへ。
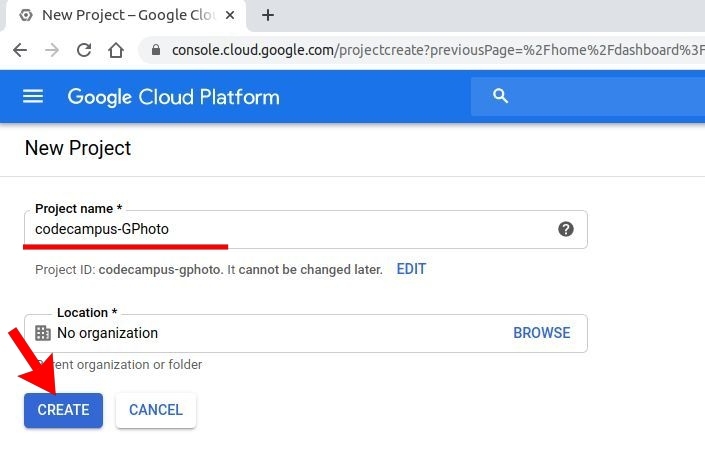
プロジェクト名を入力し、 CREATE ボタン。 30秒ぐらいで新規プロジェクトが作成されると思います。

プロジェクトの作成が完了したら画面右上のすずマークに新規プロジェクト名が登場。クリックしてプロジェクトの管理画面に移動します。

次は Google Photo API を使うための手続き。上部の検索バーに "photo" と入力する 「Photos Library API」 が表示されますのでクリック。

APIを有効にするために 「ENABLE」 ボタンをプッシュ。すると証明取得(credentials) に関するボタンが複数登場。

画面右上の 「CREATE CREDENTIALS」 と 画面左の 「Credentials」 、意味は同じと思いますが手順が異なります。今回は画面左の 「Credentials」 から認証手続きを実施。

するとまた同じような画面が表示されますが、今度はコンテンツの設定を行うために画面右の 「CONFIGURE CONTENT SCREEN」 ボタンをクリック。

コンテンツタイプを聞かれますので、下の 「External」 を選択。
個人利用の場合は、下側の 外部利用 しか選択できませんね。

お次はコンテンツの設定画面。上図の様にアプリ名を入力し、画面下の 「SAVE」 ボタン。 Google Photo API の公式ドキュメントを見ると、 URL の設定などもありますが、今回は Google Colab を使いますので、空白で SAVE。
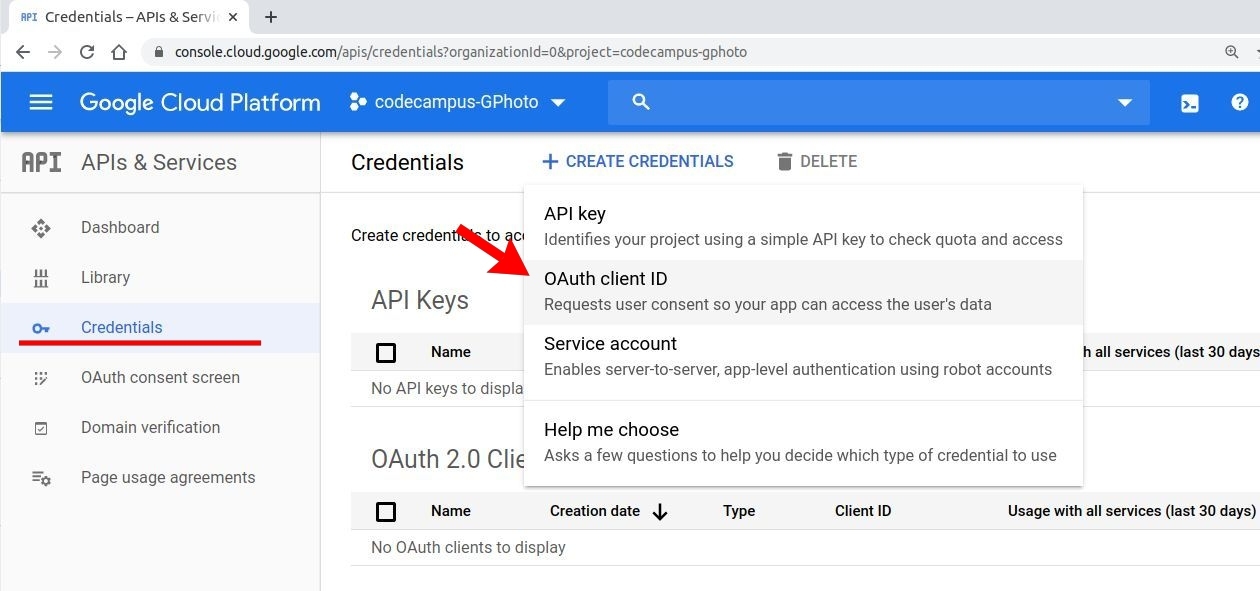
次は OAuth を取得するために、画面上部の 「+ CREATE CREDENTIALS」 をクリック。そして 「OAuth client ID」 を選択。

アプリケーションの種類は 「Other」 を選択し、 Create ボタン。

すると OAuth が作成されました。上図の Client ID や Secret は今回使用しませんので、 OK でウィンドウを閉じます。

今回は認証ファイルを使って Google Photo にアクセスしようと思いますので、 上図のように認証ファイルをダウンロード。
はじめの内はこの認証手続き面倒くさいですが、一度慣れてしまえば色々な Google API の利用時に役立ちます。

次は取得した OAuth ファイルを使って、 Google Photo へのアクセスを試みます。 Google Photo API の公式ドキュメントやサンプルを見ても OAuth に関する記述はわかりにくかったので、 YouTube API OAuth の手順で上図のように設定。 まずは必要な認証ライブラリ等をインストール。
>> Google Colaboratoryに以下コマンドをコピペ
!pip install --upgrade google-api-python-client
!pip install --upgrade google-auth google-auth-oauthlib google-auth-httplib2

次は OAuth ファイルのセット。 先ほど Google Cloud Console からダウンロードした OAuthファイル(〇〇.json) を Google Colab にアップロード。コード上では !ls とするとディレクトリ内のファイルを確認できます。

上図コード
import os
import google.oauth2.credentials
import google_auth_oauthlib.flow
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
from google_auth_oauthlib.flow import InstalledAppFlow
SCOPES = ['https://www.googleapis.com/auth/photoslibrary.readonly']
API_SERVICE_NAME = 'photoslibrary'
API_VERSION = 'v1'
CLIENT_SECRETS_FILE = 'client_secret_668378957760-c17u8nc01o5h9tf7gp52sjjqfdjhpsnn.apps.googleusercontent.com.json'
def get_service():
flow = InstalledAppFlow.from_client_secrets_file(CLIENT_SECRETS_FILE, SCOPES)
credentials = flow.run_console()
return build(API_SERVICE_NAME, API_VERSION, credentials = credentials)
service = get_service()
print(service)
認証用のライブラリ、認証ファイルが用意できたら上図のようにプログラムをコピペして、プログラムを実行。すると URL が表示されますので、クリック。

Google Photo へのアクセス許可の画面で、 OAuth を作成した自分のアカウントを選択し、手続きを進めます。

This app isn't verified
This app hasn't been verified by Google yet. Only proceed if you know and trust the developer.
【Google Translate】
このアプリは検証されていません
このアプリはまだGoogleによって確認されていません。 開発者を知って信頼している場合にのみ続行してください。
すると警告画面が。反射的に画面を閉じたくなると思いますが、この警告内容は、「このプログラムって Google で認証されていないけど、大丈夫? まあ、開発元の事を知っていたらいいけど。」 という内容。
今回自分で OAuth を作成し、認証プログラムも自分で作成していますので、大丈夫ですよね。なので画面左下の 「Advanced」 をクリック。そして アプリ名(TTT)をクリック。

アクセス許可を進めます。


コードが表示されたらコピーして、実行中のプログラム入力欄に貼り付け、リターンキーを押します。

すると問題がなければ上図の様に。これで Google Photo のデータにアクセス可能となりました。
Google Photo APIを使ってみる
API を使って Google Photo のデータにアクセスできるようになりましたが、この次のステップ、公式ドキュメントを見ても REST API のサンプルや Java、 PHP しかサンプルなく Python でどうやってデータアクセスすればいいか ??? です。
今回はいろいろ検索する中で割り出した一つの方法をご紹介。それは GitHub のコード検索で "Google Photo API" のサンプルコードを割り出したやり方です。一つの事例としてご参照ください。
データの取得

GitHub でサンプルコードを探すにしても手がかりとなるキーワードが必要。 Google Photo API のドキュメントを眺めていると、 Google Photo API 特有のコード(URL) を発見(上図)。こちらを GitHub の検索にかければ何か手がかりが見つかるかもしれません。
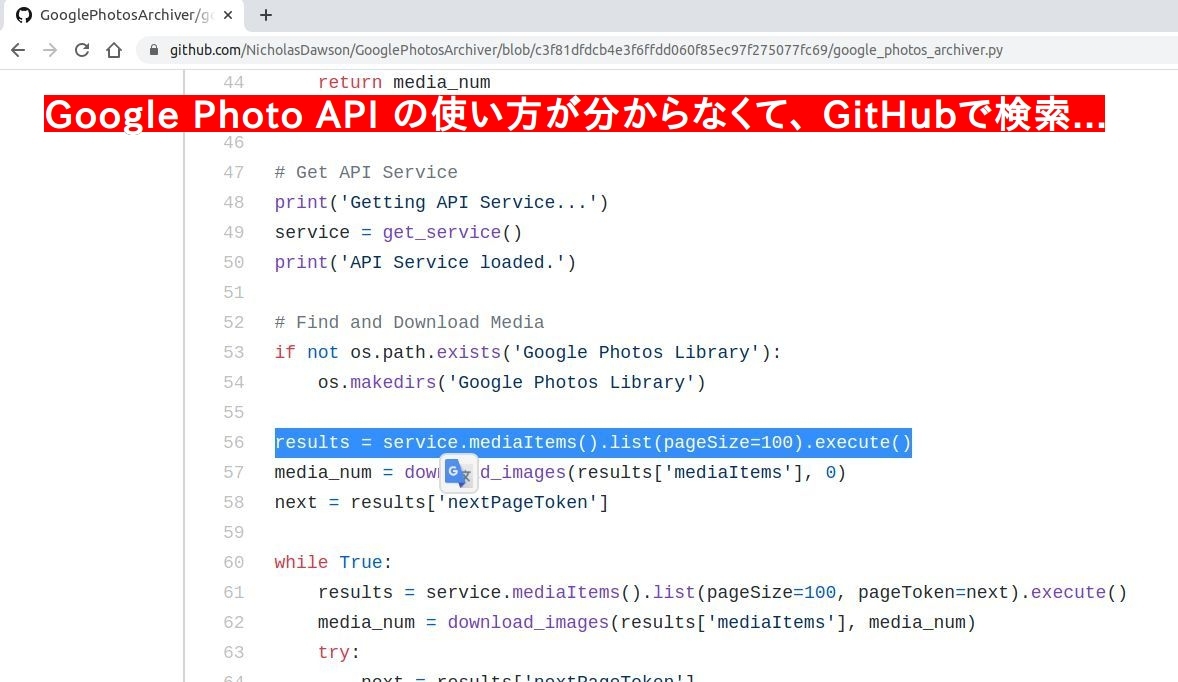
上図コード: GitHub/bylexus
そして GitHub のリポジトリやコードを検索した結果、上記のようなコードを発見。 テスト含めて 2時間かかってしまいました。そして実際に自分のプログラムでテストしてみると以下のように。
上記コードの pazeSize は、 Google Photo から取得するデータ数(アイテム点数)です。最大値は100と決められています。
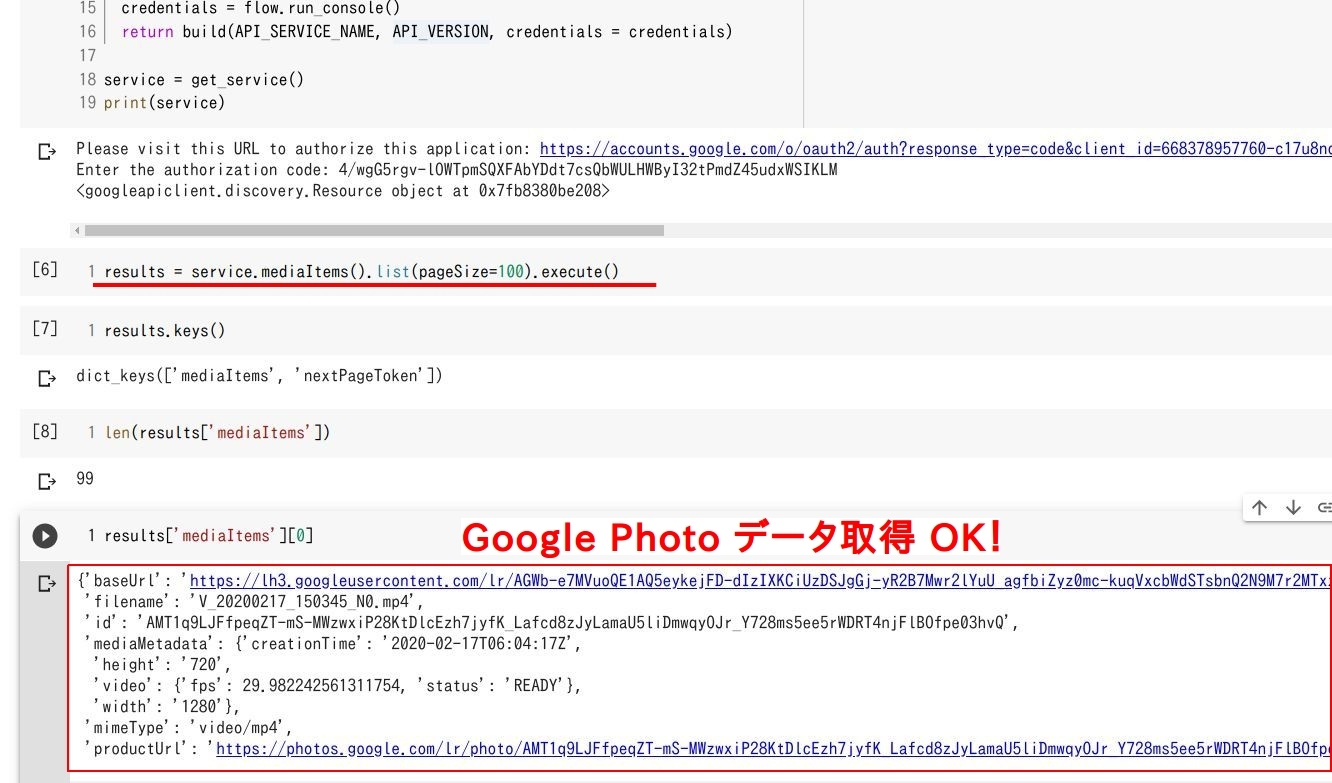
results = service.mediaItems().list(pageSize=100).execute()
GitHub のコードを参考に自分のプログラムでも実行して見ると、エラーなく mediaItems() や execute() が実行できました。 type(results) などでデータ型を確認すると dict となっていますので、 results.keys() でデータ内の様子を確認。
'mediaItems' と 'nextPageToken'がキーとして存在、参考までにアイテム数をlen(results['mediaItems']) で確認すると 99 という結果。つまり一回の処理で 99 のデータを取得可能。残りはnextPageToken` でアクセスしていく、という感じ。
参考までに取得した 'mediaItems' の中身を確認してみると、上図の様に baseUrl や ファイル名、 画像サイズにメディアタイプ といった情報が存在。 baseUrl にアクセスすると画像や動画を確認できます。
ここまでのコードを確認
!pip install --upgrade google-api-python-client
!pip install --upgrade google-auth google-auth-oauthlib google-auth-httplib2
!ls
import os
import google.oauth2.credentials
import google_auth_oauthlib.flow
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
from google_auth_oauthlib.flow import InstalledAppFlow
SCOPES = ['https://www.googleapis.com/auth/photoslibrary.readonly']
API_SERVICE_NAME = 'photoslibrary'
API_VERSION = 'v1'
CLIENT_SECRETS_FILE = 'client_secret_668378957760-c17u8nc01o5h9tf7gp52sjjqfdjhpsnn.apps.googleusercontent.com.json'
def get_service():
flow = InstalledAppFlow.from_client_secrets_file(CLIENT_SECRETS_FILE, SCOPES)
credentials = flow.run_console()
return build(API_SERVICE_NAME, API_VERSION, credentials = credentials)
service = get_service()
print(service)
results = service.mediaItems().list(pageSize=100).execute()
results.keys()
len(results['mediaItems'])
results['mediaItems'][0]
nextPageTokenで次のページを確認

先程は Google Photo API で得られるデータの 'mediaItems' を確認しました。次はもうひとつのキー 'nextPageToken' を使って、内容を確認してみたいと思います。
まず 'nextPageToken' 自体どんなものかというのは、上図セルNo.10 のように英数字の乱数であることが確認できます。そしてその 'nextPageToken' は、関数: list() 内の引数としてセット可能(セルNo.11)。これは公式ドキュメントで 'nextPageToken' を検索すれば参考コードが紹介されていました。
【最初】
results = service.mediaItems().list(pageSize=100).execute()
【今回】
results = service.mediaItems().list(pageSize=100,pageToken=results['nextPageToken']).execute()
そして results の内容が更新されたと思いますので、 results['mediaItems'][0] で取得アイテムの内容を確認(セルNo.12)。すると先ほどと内容が変わっていることが確認でき、 'nextPageToken' が上手く機能したことが確認できますね。そして "次の次のページ" は、再び results['nextPageToken'] とすることで "次の次のページ" ヘのアクセスデータを取得できます。これをひたすら繰り返せば自分の持つ Google Photo の全データにアクセスできそう。
コードを確認
results = service.mediaItems().list(pageSize=100).execute()
results['nextPageToken']
results = service.mediaItems().list(pageSize=100,pageToken=results['nextPageToken']).execute()
results['mediaItems'][0]
results['nextPageToken']
Google Photoの全データをクロール
先程までで Google Photo のアイテム確認、ページ送りを実行できましたので、次は全データをクロールできるかチェックしてみます。どれだけの数が Google Photo に保存されているか目安を確認することができますね。

上図のプログラムはとりあえず自分の Google Photo のデータを全クロールし、アイテム数をチェックするプログラム。 'nextPageToken' と while文 を使って Google Photo のデータをクロールしています。
アイテム点数は、変数: item_counter に収録され、プログラム終了後に合計値が出力されます。

私の場合は、 3310 のデータが Google Photo に保存されているというが分かりました。
あとでバックアップを実行する際にも保存したファイル数をカウントします。恐らくココで出力した合計値と違ってくるでしょう。理由は、データ取得でエラーが出たか何かで、 pageSize 100 としているにも関わらず 80ぐらいしか取得できていない時もありました。実際に試してみて下さい。
コードを確認
results = service.mediaItems().list(pageSize=100).execute()
item_counter = len(results['mediaItems']) #データ数チェック
next = results['nextPageToken']
print(item_counter)
counter = 1
while True:
print('ループ回数: ' + str(counter))
print(item_counter)
results = service.mediaItems().list(pageSize=100, pageToken=next).execute()
items = len(results['mediaItems'])
item_counter = item_counter + items
try:
next = results['nextPageToken']
counter = counter + 1
except KeyError:
break
print('合計データ数:' + str(item_counter))
Google Photoデータのダウンロード

results = service.mediaItems().list(pageSize=100).execute()
これまでの中で、上記コードで Google Photo のアイテム内容が確認。こちらのアイテムを一つダウンロードしてみたいと思います。
まず取得データの中にある baseUrl、こちらの URL にアクセスするとデータの様子が確認できますが、これはダミー。上図の例では動画のアイテムであるのに baseUrl では動画、視聴できません。
公式ドキュメントを確認すると、ビデオデータの場合は baseUrl の末尾に =dv、 画像データの場合は =d を付けてくださいと書かれています。それを試した様子が上図右側で、右下で =dv を追加した結果、ビデオデータがダウンロードされたことが確認できます。
この URL アクセスをプログラム的に処理した内容が下記プログラム。
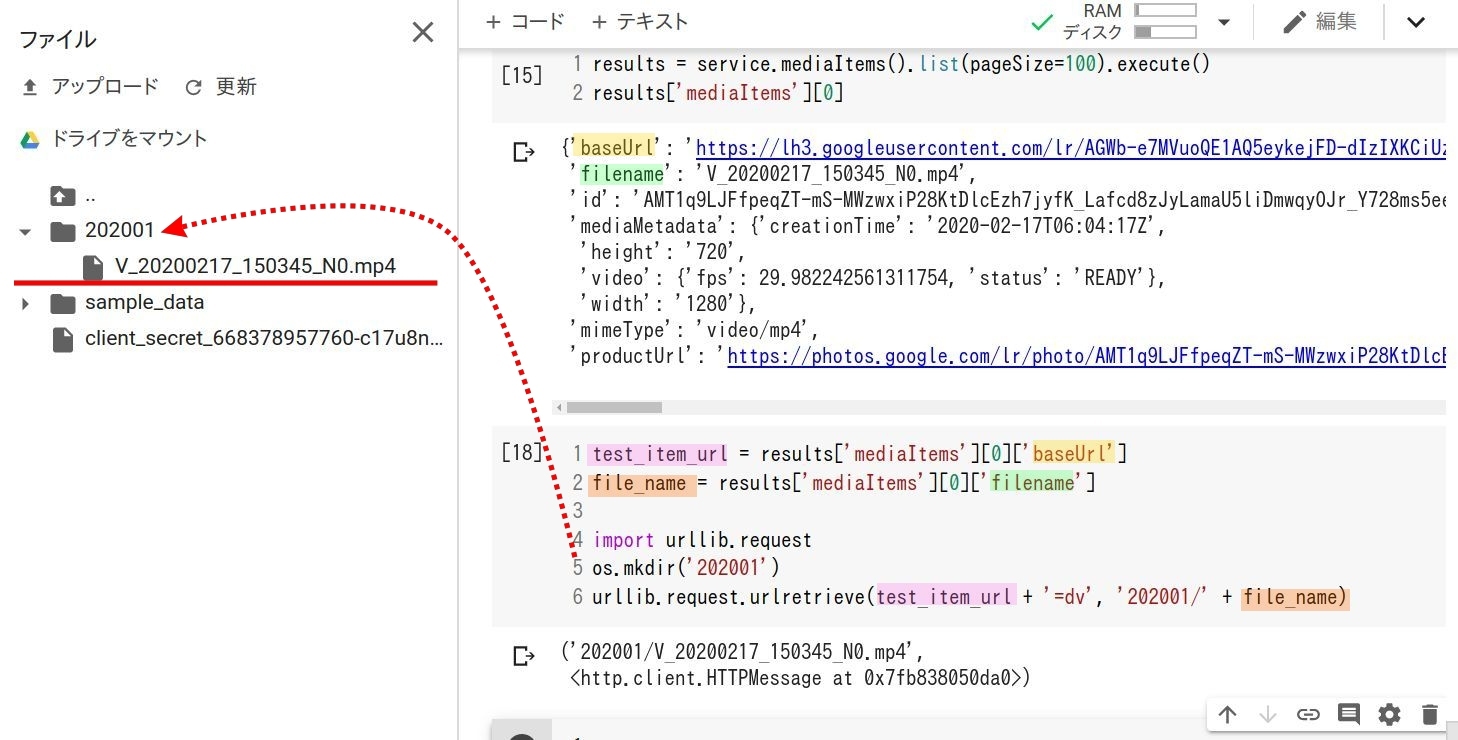
Google Photo API で画像・ビデオデータにアクセスし、任意のフォルダに保存する様子
まずダウンロードしたいアイテムは 'baseUrl' がキーとなり、その末尾には =dv や =d の追加が必要。それらを制御しやすくするために baseUrl を変数: test_item_url に格納。
そして保存する際のファイル名は、 Google Photo の 'filename' を利用し、変数: file_name に。。
Python を使ってデータをダウンロードする方法はいくつかありますが、今回は Python の標準モジュールとしてセットされている urllib.request を使用。 urllib.request を使ってデータをダウンロードするコードは、以下のように "ダウンロード元のURL" と "ファイル名" の指定だけで OK。
urllib.request.urlretrieve(データURL, 保存するファイル名)
今回は Google Photo 内のファイル名が、 P_20200217.... 、 V_20200121... と日付名で概ねストックされていますので、月別フォルダにデータを保存していくことに。 Pythonでフォルダを作成するには、 os.mkdir('フォルダ名') とすれば OKで、仮に 「202001」 というフォルダを作成し、保存するようコードを書くと上図のように。
プログラムを実行すると、 202001フォルダが作成されて、その中に Google Photo アイテムが保存されたことが確認できます(上図参照)。
こちらのコードを確認
results = service.mediaItems().list(pageSize=100).execute()
results['mediaItems'][0]
test_item_url = results['mediaItems'][0]['baseUrl']
file_name = results['mediaItems'][0]['filename']
import urllib.request
os.mkdir('202001')
urllib.request.urlretrieve(test_item_url + '=dv', '202001/' + file_name)
保存先の振り分け(月別)
先程は任意のフォルダを作成し、その中に Google Photo のデータを保存しました。こちらではアイテムのファイル名から、そのデータの "月" を判別し、該当年月フォルダに保存していきます。
まずは一つのデータを対象に、振り分けをテスト。

上図のコードを確認
# 月別フォルダ、データ種類別保存処理
results = service.mediaItems().list(pageSize=100).execute()
file_name = results['mediaItems'][0]['filename']
folder_name = file_name[2:8]
item_url = results['mediaItems'][0]['baseUrl'] #image, video data
print(file_name)
print(folder_name)
def data_save():
# image or video
if file_name[0] == 'P':
print('img')
urllib.request.urlretrieve(item_url + '=d', folder_name + '/' + file_name)
elif file_name[0] == 'V':
print('video')
urllib.request.urlretrieve(item_url + '=dv', folder_name + '/' + file_name)
else:
print('あれ、このデータは何だ...')
print(file_name)
if os.path.isdir(folder_name):
print('フォルダあるよ')
data_save()
else:
print('フォルダないよ')
os.mkdir(folder_name)
data_save()
各変数を色分けし、結果が上図の様に表示されていますので、概ねプログラムの流れは分かると思いますが、補足します。
まずいろいろコードが書かれていますが、最初の実行部分は下部 21 〜 27行目で、 Google Photo から取得したデータを元に該当フォルダの有無をチェック。該当フォルダがある場合、ない場合で処理を振り分け、該当フォルダがなければ os.mkdir(フォルダ名) で新規フォルダを作成。そしてそのフォルダに Google Photo データを保存、ということですが、データがビデオなら baseUrl末尾に =dv とかビデオと画像では処理に違いが。
この取得データによって URL を変える処理を関数: data_save() に収録。
上図ではファイル名の頭文字からそのデータが "画像" か "動画" か判断しています。
このプログラムを実行すると上図のように、 フォルダ: 2020 に Google Photo データが保存できたことが確認。
ちなみに今回はファイル名を元に "画像" "動画" を判断し、月別もファイル名から判断しています。決まった端末からだけのデータであれば概ね上手くいきそうですが、ファイル名がバラバラだと無作為にフォルダが作成されて分かりにくくなってしまいます。
この問題は、 Google Photo からのデータを利用すると解決可能。例えばデータタイプは、 'mimeType' というキーを利用すれば OK(下図参照)。

上図のコードを確認
data_type = results['mediaItems'][0]['mimeType']
print(data_type)
if 'image' in data_type:
print('画像データ')
elif 'video' in data_type:
print('videoデータ')
else:
print('何だこのデータは...')
上図はデータの種類をファイル名から判別するのではなく、 Google Photo API から取得した 'mimeType' を使って判定する例。

こちらはデータの日付をファイル名から判定するのではなく、 API で取得したデータ 'mediaMetadata' を使う例。今回はファイル名からプログラム処理する方が簡単なので、上記の方法は用いません、ご了承ください。
Google Photo APIでバックアップを実行
これまでの流れで、以下のことができるようになりました。
- Google Photo API で Google Photo のデータにアクセス
- Google Photo のデータをダウンロード
- Google Photo のデータを月別に保存
これらを上手く組み合わせると、 Google Photo 内の全データをバックアップできそうですね。

上図のコードを確認
import os
import google.oauth2.credentials
import google_auth_oauthlib.flow
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
from google_auth_oauthlib.flow import InstalledAppFlow
import urllib.request
SCOPES = ['https://www.googleapis.com/auth/photoslibrary.readonly']
API_SERVICE_NAME = 'photoslibrary'
API_VERSION = 'v1'
CLIENT_SECRETS_FILE = 'client_secret_668378957760-c17u8nc01o5h9tf7gp52sjjqfdjhpsnn.apps.googleusercontent.com.json'
def get_service():
flow = InstalledAppFlow.from_client_secrets_file(CLIENT_SECRETS_FILE, SCOPES)
credentials = flow.run_console()
return build(API_SERVICE_NAME, API_VERSION, credentials = credentials)
service = get_service()
results = service.mediaItems().list(pageSize=100).execute() # pageSize最大100
item_counter = len(results['mediaItems']) #item_counter max 99
next = results['nextPageToken']
# ファイル数 99/page
counter = 1
def save_data():
global counter
items_per_page = 0
while items_per_page < item_counter:
file_name = results['mediaItems'][items_per_page]['filename']
item_url = results['mediaItems'][items_per_page]['baseUrl']
data_type = results['mediaItems'][items_per_page]['mimeType']
folder_name = file_name[2:8]
def data_save():
# image or video
if 'image' in data_type:
try:
urllib.request.urlretrieve(item_url + '=d', folder_name + '/' + file_name)
except:
print('save error...')
print(file_name)
elif 'video' in data_type:
try:
urllib.request.urlretrieve(item_url + '=dv', folder_name + '/' + file_name)
except:
print('save error...')
print(file_name)
else:
print('あれ、このデータは何だ...error,,,')
print(file_name)
if os.path.isdir(folder_name):
data_save()
else:
os.mkdir(folder_name)
data_save()
print(str(counter))
items_per_page += 1
counter += 1
save_data()
while True:
results = service.mediaItems().list(pageSize=100, pageToken=next).execute()
item_counter = len(results['mediaItems'])
save_data()
try:
next = results['nextPageToken']
counter = counter + 1
except KeyError:
break
print('バックアップしたファイル数:' + str(counter))
Google Photo のバックアップ・プログラム、 1つのファイルに書いたところ 80行ぐらいになり、画像では分かりにくいため、処理工程に興味ある方は上記の詳細コード・タブで確認してください。そしてプログラムを実行した結果が下記の様子。

Google Photo のファイル名から "月別" でファイルを自動保存する様子。
3300ぐらいのデータで、バックアップには 約 30分かかりました。尚、今は Google Colab 上でプログラムを実行していますので、テスト・バックアップです。このプログラムを自分のパソコンで実行すれば自分のパソコンにバックアップ取れますし、 Oracleクラウド上で実行すれば Oracle クラウド上にバックアップを取れます。
基本 Python の実行環境とオンライン環境があれば OK ですが、セキュリティー面には気をつける必要があるでしょう。
OracleクラウドにGoogle Photoのデータをバックアップ
それではココから Oracleクラウドで Google Photo バックアップ・プログラムを実行する準備をしていきます。

まずは Google Colab で作成したプログラムを Pythonファイルに記録します。そしてプログラムに必要な Google Photo API の OAuthファイルもまとめて一つのフォルダに格納。このときこのプログラムと関連する Googe Cloud プロジェクト名やコードテストした Colab の URL などを READMEファイルなど作成してメモ記録しておきましょう。
今回 Oracleクラウドで実行するプログラム 2種
プログラム① how_many.py
import os
import google.oauth2.credentials
import google_auth_oauthlib.flow
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
from google_auth_oauthlib.flow import InstalledAppFlow
import urllib.request
SCOPES = ['https://www.googleapis.com/auth/photoslibrary.readonly']
API_SERVICE_NAME = 'photoslibrary'
API_VERSION = 'v1'
CLIENT_SECRETS_FILE = 'client_secret_668378957760-c17u8nc01o5h9tf7gp52sjjqfdjhpsnn.apps.googleusercontent.com.json'
def get_service():
flow = InstalledAppFlow.from_client_secrets_file(CLIENT_SECRETS_FILE, SCOPES)
credentials = flow.run_console()
return build(API_SERVICE_NAME, API_VERSION, credentials = credentials)
service = get_service()
results = service.mediaItems().list(pageSize=100).execute()
item_counter = len(results['mediaItems'])
next = results['nextPageToken']
counter = 1
while True:
print('ループ回数: ' + str(counter))
results = service.mediaItems().list(pageSize=100, pageToken=next).execute()
items = len(results['mediaItems'])
item_counter = item_counter + items
try:
next = results['nextPageToken']
counter = counter + 1
except KeyError:
break
print('Google Photo のファイル合計数' + str(item_counter))
import os
import google.oauth2.credentials
import google_auth_oauthlib.flow
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
from google_auth_oauthlib.flow import InstalledAppFlow
import urllib.request
SCOPES = ['https://www.googleapis.com/auth/photoslibrary.readonly']
API_SERVICE_NAME = 'photoslibrary'
API_VERSION = 'v1'
CLIENT_SECRETS_FILE = 'client_secret_668378957760-c17u8nc01o5h9tf7gp52sjjqfdjhpsnn.apps.googleusercontent.com.json'
def get_service():
flow = InstalledAppFlow.from_client_secrets_file(CLIENT_SECRETS_FILE, SCOPES)
credentials = flow.run_console()
return build(API_SERVICE_NAME, API_VERSION, credentials = credentials)
service = get_service()
results = service.mediaItems().list(pageSize=100).execute() # pageSize最大100
item_counter = len(results['mediaItems'])
next = results['nextPageToken']
counter = 1
def save_data():
global counter
items_per_page = 0
while items_per_page < item_counter:
file_name = results['mediaItems'][items_per_page]['filename']
item_url = results['mediaItems'][items_per_page]['baseUrl']
data_type = results['mediaItems'][items_per_page]['mimeType']
folder_name = file_name[2:8]
def data_save():
# image or video
if 'image' in data_type:
try:
urllib.request.urlretrieve(item_url + '=d', folder_name + '/' + file_name)
except:
print('save error...')
print(file_name)
elif 'video' in data_type:
try:
urllib.request.urlretrieve(item_url + '=dv', folder_name + '/' + file_name)
except:
print('save error...')
print(file_name)
else:
print('あれ、このデータは何だ...error,,,')
print(file_name)
if os.path.isdir(folder_name):
data_save()
else:
os.mkdir(folder_name)
data_save()
print(str(counter))
items_per_page += 1
counter += 1
save_data()
while True:
results = service.mediaItems().list(pageSize=100, pageToken=next).execute()
item_counter = len(results['mediaItems'])
save_data()
try:
next = results['nextPageToken']
counter = counter + 1
except KeyError:
break
print('バックアップしたファイル数:' + str(counter))

そして次は Oracleクラウドに Python ファイルや OAuthファイルを転送。今回は上図のように FTPソフトを使って、 Oracleクラウドの フォルダ: GooglePhotoBackup 内に保存。
「えっ、Oracleクラウドの設定は?」 という方は、こちらの動画 「How to Use Oracle Cloud(オラクル・クラウドの基本的な使い方)」 をご参照下さい。また FTPソフトについては、 「FileZilla 使い方」 などでググればたくさん情報が出てくると思います。 FTP なしでパソコンから Oracleクラウドにファイル転送する場合は、 以下の scp コマンドで OK。
scp -i キーファイル名 /home/oshimamasara/ファイル名 ubuntu@129.146.186.166:/home/ubuntu/ディレクトリ名/
GitHub にファイルをアップして、 Oracleクラウドから git clone する際は、 OAuth などのセキュア情報に気を付けて下さい。

上図は自分のパソコンと Oracleクラウドを接続して作業している様子
Oracleクラウドに実行ファイルが用意できたら、次はプログラムの実行環境を整備。今回は Google Photo API の OAuth を利用しますので、 Colab でも実行した下記 OAuth用ライブラリをインポート。
pip install --upgrade google-api-python-client
pip install --upgrade google-auth google-auth-oauthlib google-auth-httplib2
(上図では仮想環境なしで pip install していますが、このあたりはお好みで実行して下さい)
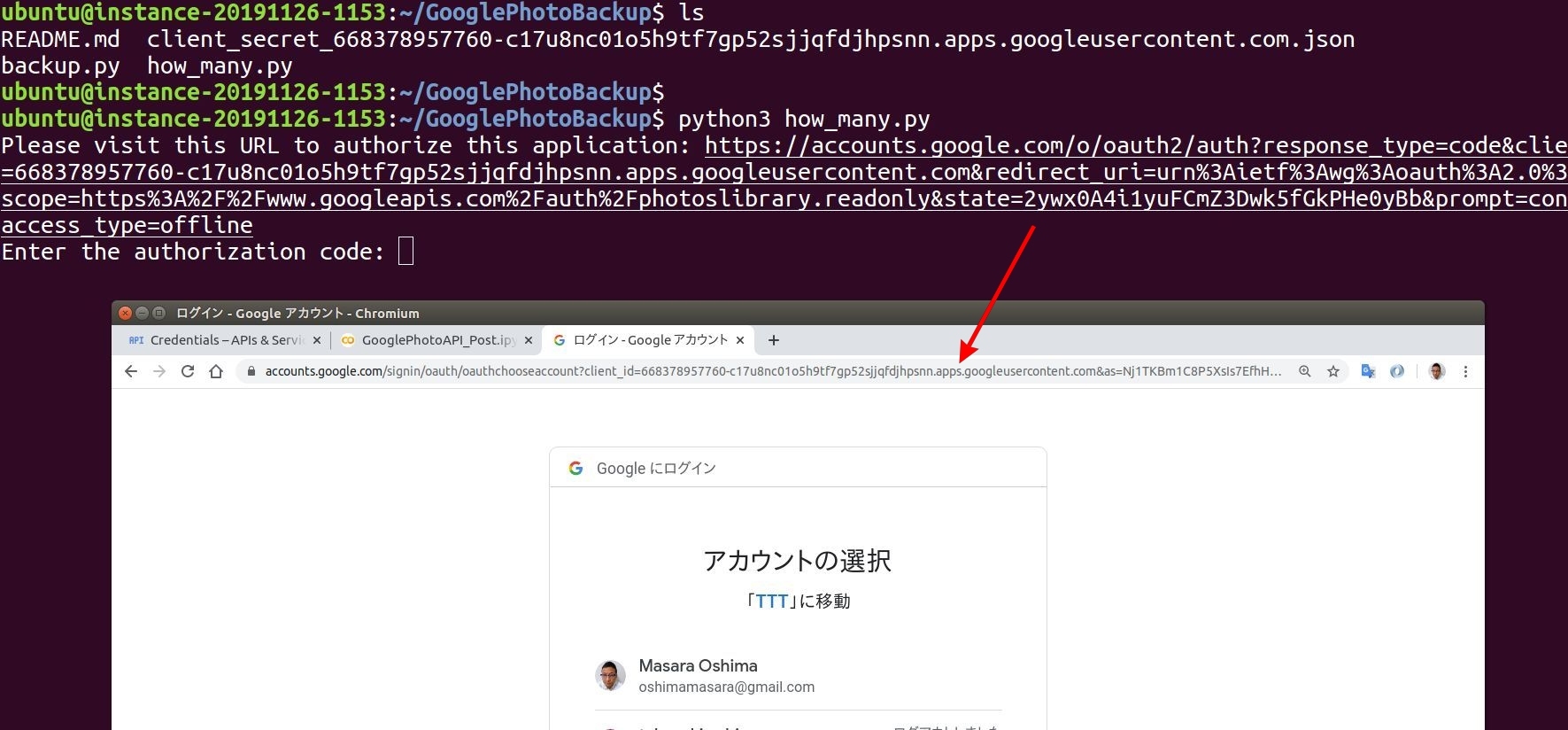
pip install が完了したら次はプログラムの実行です。まずは Google Photo 内のデータ数をカウントするプログラム: how_many.py を実行してみます。 python3 how_many.py を実行すると URL が表示、こちらの URL をコピーして、自分のパソコンのブラウザでアクセス。すると Google のアカウント認証プロセスが実行されますので、進めます。

Google認証プロセスで紹介された "認証コード" をコマンドに貼り付け、リターンキーを押すとプログラムが実行。 5分ほど待つと下図のようにプログラムが完了したことが確認できます。
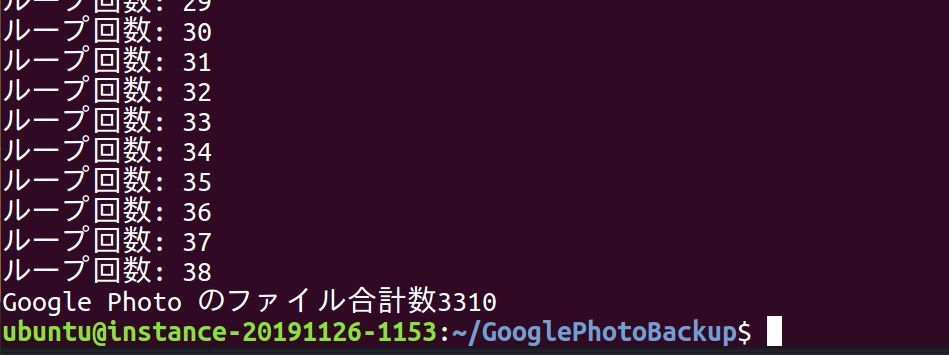

先ほどと同じようにバックアップ・プログラムを実行。 30分ほどすると 3300 程のデータが Oracle クラウドに保存できたことが確認できます。


Oracleクラウドに保存したデータは、コマンド上では内容を確認しにくいですが、 FTPソフトを利用すれば自分のパソコンからバックアップのデータ内容を確認可能(下図)。

今回 Google Photo のバックアップ前後での Oracleクラウド・コンピューティング状況は以下のように。

概ね 3300 のデータ保存に 5.5GB ほど容量が消費されました。しかし、まだ 30GB 以上の空きがあります。
今回のバックアップに関する補足事項
セキュリティについて
今回高いレベルの個人情報を Oracleクラウドのコンピューターにバックアップしました。 基本 Oracle クラウドには SSHキーがないとアクセスできないので、キーを保管する自分のパソコンからのみのアクセスとなります。
バックアップ・データについて
今回はシンプルな処理を意識しましたので、 Google Photo 内のデータを単に "画像ファイル" や "動画ファイル" として保存。 もっと使いやすくしようと思うとデータベースに保存し、サーバー機能なんかも搭載すればオリジナルのフォト管理アプリも作成可能でしょう。
APIの利用制限について
Google Photos Library API は、 1日あたり 10,000回までのリクエストになります。 利用状況については Quotas より確認してみて下さい。
尚、本稿によって Google Photo に障害、データ損失、情報漏えいが起きた場合も当該は一切の責任を負いません。予めご了承下さい。
Google Photo APIでデータをバックアップする様子の動画
本稿と合わせてご紹介下さい。
今回のコードを収めた Google Colab
\AIエンジニアに必要なスキルが身に付く/
まとめ
今回は 3,000枚程度のデータ処理でしたが、 数万、数十万の Google Photo のデータ処理となると、 API がないとちょっとキツそうですね。また今回はバックアップのみのデータ処理でしたが、 Google Photos Library API ではデータ削除やアップロードなど様々な処理をプログラム的に実行可能。アプリ開発の "幅" が広がりそう。
「API ってなんだかいろいろできそうだけど、それ以前にプログラミングが全然わからない」 「Google Photo の画像データを AI でラーニングさせたら、なんか面白そう...」 と思うものの、前に進まないあなた。 チョット勇気を出して、自分が前に進まなきゃ、何も変わりません。逆に自分で前に進み、ナニか行動すると "変わる" ということ。
「そういえば今日は早く帰れるな」 「今度の休み、何しようかな...」 という方、一度 CodeCamp の "無料体験" どうでしょうか? 「いやいや、どうせお金ないし...」 「勧誘が怖い...」 いろいろ不安に思うことはあると思いますが、一部上場企業グループに属する CodeCamp なら一定の安心感は持って頂けると思いますし、 「お金」 についても価値相応のものかどうか、確認してみませんか?
10年後、20年後ますます進化するであろう "ITデータ社会" に対応するには、すこし自己投資が必要な時かもしれません。 無料体験やレッスンコースについては、 公式ページ よりチェックしてみて下さい。 明るい未来... 手に入れたいですね。







- この記事を書いた人
- オシママサラ








