- 更新日: 2019年10月3日
- 公開日: 2019年10月1日
【AI入門】オリジナルの画像を機械学習させて判定させてみよう

AI や 機械学習の勉強をはじめた時、 よく画像認識の MNIST という数字認識のサンプルを体験する方も多いと思います。
また他にも花の種類を識別するサンプルなどいろいろ公開されていますが、自分のオリジナルの画像を機械学習させて、認識してもらいたいって思ったことはありませんか?
今回は Google Codelabs に公開されてるチュートリアルを元に、 ”クモ” を識別してみました。
【AI入門】オリジナルの画像を認識させて判定させてみよう
オリジナルの画像を認識させる方法

Google Cloud Platform の AutoML Vision の様子
今回は Google Codelabs の 「Tensorflow For Poets」 という 2017年公開のチュートリアルを参考にしますが、他にもオリジナルの画像を認識させる方法あります。
一番上の Google Cloud Platform は有料サービスで、プログラミング知識不要でも機械学習を用いて画像解析・画像認識できるのですが、高いです。サーバーに画像データをセットするためのストレージ費用、機械学習のためにサーバー・マシンを動かす費用、学習済みのデータ(モデル)を公開・運営するための費用。日々刻々と利用時間と共に料金が発生します。 100KB程の画像データをアップし、標準的な機械学習、そして 1node でデプロイしましたが、 1日で 5000円程発生。
それに対して tf.data や tf.keras などを使う場合は、予め自分のパソコンで学習し、出来上がったモデルのみをサーバーやアプリにデプロイすれば OK。感覚的には半分以下のコストで運営できるでしょう。 そうしたコスト的なこともあり、やはり自分である程度画像解析できた方がお得。
また tf.data 、 tf.keras などある中で 「Tensorflow For Poets」 を選んだ理由としては、必要なファイルや手順がまとまって、シンプルで短くわかりやすいため。直感的に自分の画像を学習させて、類似画像の予測までスムーズに実行できます。
それでは 「Tensorflow For Poets」 を実行していきましょう。
実行環境

いつも通りのパソコンで実行できます。
コンピューター/ GitPod
言語/ Python Version 2
フレームワーク/ TensorFlow Version 1.4
ローカル環境ではなく GitPod を選んだ理由としては、
- 一時的なテストプログラムのため
- ローカル環境において TensorFlow 1.4 はメインでないため
- ローカルは Python3 メインのため
- WindowsユーザーでもMacユーザーでも GitPod上では同じ Linux 環境となるため(説明の統一化)
今回の 「Tensorflow For Poets」 と 「Hub 0.4 の再トレーニング(retrain.py)」 は、 Python2 の実行環境。普段自分のパソコンは Python3 メインとなっているため、何かと使い勝手が変わってややこしいと思い、仮想環境のマシンを選択。参考ソースが GitHub 上のものなので、 GitHub と親和性の高い GitPod を選択、という訳です。失敗してもマシンを消したり、作ったり気軽に無料で利用できるので Good ですね。
尚、GitPod の利用には GitHub のアカウントが必要となってきます。まだの方はこれを機会に作成しておきましょう。
データの用意

画像クリックで拡大
今回は ”クモ” の種類を認識してもらうためのプログラムとしたいので、”クモ” データをランダムに収集。プライベート利用として、 Google イメージ検索でランダムに 「タランチュラ」 と 「セアカコケグモ」 の画像をダウンロードしました。
タランチュラ画像引用:Google/Image
セアカゴケグモ画像引用:Google/Image
通常画像に関する学習データは、数万枚必要というところですが、今回は 10枚程度で学習。今回は認識レベルを上げるよりも、とりあえずのフロー確認のため、データの用意は手抜きとさせて頂きました。

画像クリックで拡大
これらの画像データを MLDataフォルダの中の 「seaka」 と 「tarantyura」 フォルダに分けて保存。 seaka や tarantyura というフォルダ名が、画像認識の時の名称になります。
これでデータの用意は完了。次はコンピューターに画像認識してもらうように機械学習を行います。
自分の画像を機械学習
「Tensorflow For Poets」 に従って自分の画像を機械学習させようと思いますが、こちらの場合は「転移学習」つまり再トレーニングで画像を学習。スタンフォード大学やプリンストン大学が運営する IMAGENET の学習済みモデルを使って、早く画像解析を行う予定。
現在 IMAGENET には 1000以上の画像が学習済みとして登録されています(画像ラベルリスト)。 この中に ”クモ” も 4種類ほどデータ・セットされていますが、”タランチュラ” や ”セアカゴケグモ” はありません。
実行プログラムの準備

画像クリックで拡大
https://gitpod.io/#https://github.com/googlecodelabs/tensorflow-for-poets-2
とりあえずまずは GitPod のマシーンにプロジェクトをインポート。上記 URL を ブラウザで検索すると、自動的に GitPod マシンが起動し、 git clone されます。

画像クリックで拡大
pip install --upgrade "tensorflow==1.7.*"
GitPod マシンが起動したら、 TensorFlow をインストール。この時他のバージョンをインストールしないように、 1.7 をインストールしましょう。違うバージョンをインストールすると、 scripts フォルダ内の Python ファイルが上手く動かない可能性があります。インストールが正常に完了すると以下の様に。

画像クリックで拡大
GitPodマシンに画像をアップロード

画像クリックで拡大
次はクモの画像を GitPodマシンにアップします。画像をアップする前に tarantyura と seaka のフォルダを作成。アップロードはファイルのみ対応で、フォルダ丸ごとはアップできません。
tf_files フォルダ下に MLDataフォルダを作って、 MLDataフォルダの下に seaka と tarantyura フォルダを作成。新規フォルダの作成は「右クリック → New Folder」で作れます。そして seaka フォルダに自分のパソコンのセアカゴケグモの画像ファイルをアップロード。 tarantyura についても同様に画像ファイルをアップします。尚、画像ファイルのアップロードは、 seaka フォルダで右クリック → Upload Files... で手続きできます。
学習後のテスト画像も同様にフォルダを作って、画像ファイルをアップしておきましょう。画像ファイルをダブルクリックして、画像が表示されれば OK(下図参照)。

画像クリックで拡大
再トレーニングの設定

画像クリックで拡大
IMAGE_SIZE=224
ARCHITECTURE="mobilenet_0.50_${IMAGE_SIZE}"
今回 GitHub からインポートした Pythonファイルでは、 MobileNet という学習済みモデルを使って、自分のオリジナル画像を機械学習します。 現在 MobileNet は、バージョン 1 と バージョン 2がありますが、今回はバージョン 1。
そして MobileNet を使う上で「入力画像の解像度」と「どれぐらいの割合で MobileNet を使うか」という設定を事前に行っておく必要があります。この「解像度」と「割合」の設定は、 GitPod マシンに直接行う必要があるので、上記コマンドをターミナルに入力し、実行。このとき「Tensorflow For Poets」のチュートリアル・コードをそのままコピペすると、下記のようなエラーがでます。
bash: IMAGE_SIZE: command not found
bash: ARCHITECTURE: command not found
エラーが出る理由としては = の両サイドにスペースがあるため。他にも不要なスペースがあるので、削除して実行すると上手くいきます。このようにチュートリアル通りやっても上手くいかない時、実はムチャクチャ単純なミスが原因であることはよくあります。
IMAGE_SIZE については、 128、160、192、224 とある中から今回は 224 を選択。サイズが大きいと学習レベルは上がりますが、学習に時間がかかります。最初の内はいろいろ数字を変えて、試してみるといいですね。 また ARCHITECTURE は、 MobileNet の学習済みデータをどれぐらい使うか、というもの。こちらも 1.0、 0.75、 0.50、 0.25 とある中から半分の 0.5 を選択。このあたりのパラメーター設定、どれがいいかは難しいですが、今回の 224 と 0.5 だったら数分で再トレーニングが終わるので、精度を優先しないならとりあえず OK でしょう。
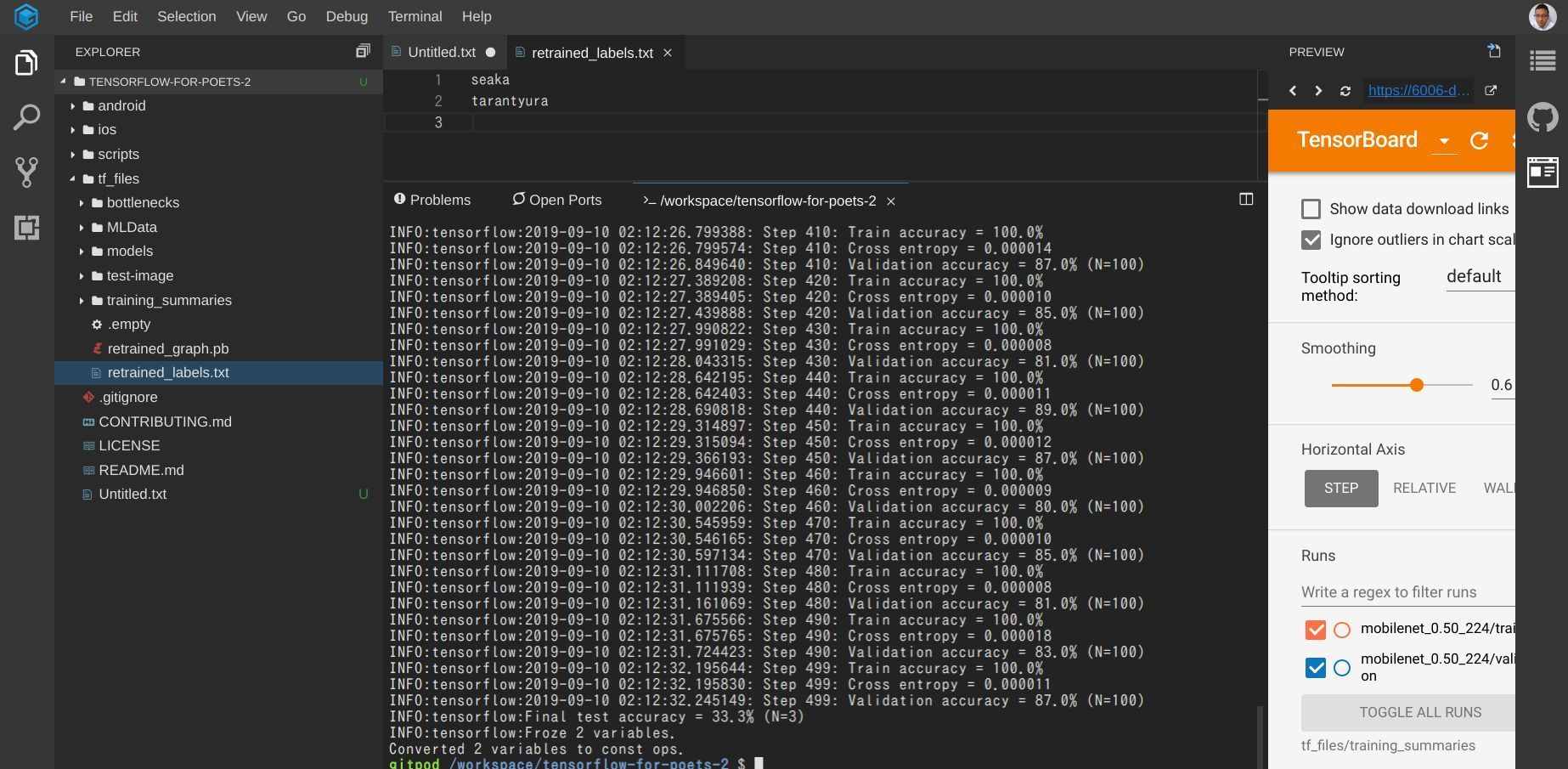
TensorBoard

画像クリックで拡大
tensorboard --logdir tf_files/training_summaries &
チュートリアルには TensorBoard の起動も書かれていますので、実行しておきます。最トレーニングの様子を可視化してくれますが、内容は難しいです。 TensorFlow にはこんな機能もあるんだな、という程度で最初はいいと思います。
上記コマンドを実行すると、画面上部にボタン「Expose」が登場、クリックして、「Open Preview」を選択。すると GitPod でも TensorBoard を確認できます。
再トレーニング実施

画像クリックで拡大
python -m scripts.retrain\
--bottleneck_dir=tf_files/bottlenecks\
--how_many_training_steps=500\
--model_dir=tf_files/models/\
--summaries_dir=tf_files/training_summaries/"${ARCHITECTURE}"\
--output_graph=tf_files/retrained_graph.pb\
--output_labels=tf_files/retrained_labels.txt\
--architecture="${ARCHITECTURE}"\
--image_dir=tf_files/MLData
オリジナルの画像をコンピューターに認識してもらうために、 retrain.py というプログラムを実行します。上記コマンド、一見すると「大層な処理内容だな」と思うかもしれませんが、一つ一つ確認してくとそれほど複雑なモノではありません。
上記コマンドの解説
【一行目 python -m scripts.retrain】 scriptsフォルダ内の retrain.py を実行
【二行目 --bottleneck_dir=tf_files/bottlenecks】 ボトルネックは、再トレーニングでオリジナル画像がニューラルネットワーク処理された証。今回学習済みの MobileNet を使っていますので、その最終レイヤーにボトルネックが加わって、学習された形。画像の枚数分、ボトルネックは生成されます。(下図参照)
 【三行目 --how_many_training_steps=500】 再トレーニングの回数、今回は 500回。 500でも多いように思いますが、実はデフォルト設定だと 4000回。学習精度を高めたい時は 4000 とか必要でしょうが、今回は流れの確認なので 500。
【四行目 --model_dir=tf_files/models】 こちらは事前トレーニング済みの MobileNet を保存する先を指定。下図のように 1000以上の画像が学習済み。
【三行目 --how_many_training_steps=500】 再トレーニングの回数、今回は 500回。 500でも多いように思いますが、実はデフォルト設定だと 4000回。学習精度を高めたい時は 4000 とか必要でしょうが、今回は流れの確認なので 500。
【四行目 --model_dir=tf_files/models】 こちらは事前トレーニング済みの MobileNet を保存する先を指定。下図のように 1000以上の画像が学習済み。
 【五行目 --summaries_dir=tf_files/training_summaries/"${ARCHITECTURE}"】 こちらは TensorBoard 用のデータ出力。
【六行目 --output_graph=tf_files/retrained_graph.pb】 再トレーニングしたモデルを retrained_graph.pb として出力。最終的にアプリにこのモデルをセットする時は .pb ファイルを TensorFlow Lite 形式に変換して使用します。
【七行目 --output_labels=tf_files/retrained_labels.txt】 再トレーニングした結果のラベル。画像解析した結果、その画像が何であるかが retrained_labels.txt にまとめられています。ちなみに今回は下図のように seaka と tarantyura のみ、画像のフォルダ名が引用されていますね。
【五行目 --summaries_dir=tf_files/training_summaries/"${ARCHITECTURE}"】 こちらは TensorBoard 用のデータ出力。
【六行目 --output_graph=tf_files/retrained_graph.pb】 再トレーニングしたモデルを retrained_graph.pb として出力。最終的にアプリにこのモデルをセットする時は .pb ファイルを TensorFlow Lite 形式に変換して使用します。
【七行目 --output_labels=tf_files/retrained_labels.txt】 再トレーニングした結果のラベル。画像解析した結果、その画像が何であるかが retrained_labels.txt にまとめられています。ちなみに今回は下図のように seaka と tarantyura のみ、画像のフォルダ名が引用されていますね。
 【八行目 --architecture="${ARCHITECTURE}"】 こちらは事前学習済みモデル MobileNet の占める割合。前章のコマンドで実行した ARCHITECTURE="mobilenet_0.50_${IMAGE_SIZE}" が引用。
【九行目 --image_dir=tf_files/MLData】 学習してもらいたいデータのディレクトリ。今回は MLData 内の seaka と tarantyura フォルダを学習してもらいました。ここに学習させたいデータのディレクトリを指定します。
【八行目 --architecture="${ARCHITECTURE}"】 こちらは事前学習済みモデル MobileNet の占める割合。前章のコマンドで実行した ARCHITECTURE="mobilenet_0.50_${IMAGE_SIZE}" が引用。
【九行目 --image_dir=tf_files/MLData】 学習してもらいたいデータのディレクトリ。今回は MLData 内の seaka と tarantyura フォルダを学習してもらいました。ここに学習させたいデータのディレクトリを指定します。
画像クリックで拡大
今回の場合は 20枚ぐらいの画像なので 1分ぐらいで再トレーニング終了。 TensorBoard も先ほどまでは何も表示されていなかったのですが、再トレーニングによって行われた内容が表示されています。

画像クリックで拡大
いろいろクリックして、内容を確認してみて下さい。先ほどの一回のコマンドでいろんなことが行われていることが確認できると思います。
オリジナル画像を学習させた結果の検証

画像クリックで拡大
【検証①】
python -m scripts.label_image\
--graph=tf_files/retrained_graph.pb\
--image=tf_files/test-image/test1.jpeg
【検証②】
python -m scripts.label_image\
--graph=tf_files/retrained_graph.pb\
--image=tf_files/test-image/test2.jpg
上記コマンドの解説
【一行目 python -m scripts.label_image】 scriptsフォルダ内の label_image.py を実行
【二行目 --graph=tf_files/retrained_graph.pb】 使用するモデル(学習済みデータ)の選択。 retrained_graph.pb は、先ほど再トレーニングしてできたオリジナルの学習済みデータ
【三行目 --image=tf_files/test-image/test1.jpeg】 テストする画像を指定。学習に用いた画像でも OK。
学習には用いなかったタランチュラとセアカゴケグモの画像をコンピューターに認識させたところ、タランチュラについては 98.875% でタランチュラでしょ、セアカゴケグモについては 100% セアカゴケグモ でしょ、という非常に高い確率で認識。スゴイですね。
今回は 2種類のクモの画像認識でしたが、もっと増やすと「家の壁をはっているクモ、大丈夫か?」と思った時の判定アプリになるでしょう。再トレーニングで生成された retrained_graph.pb を TensorFlow Lite 形式に変換すれば Android や iPhone などのスマホでも画像認識できるようになるので、なんかアプリ開発もおもしろくなりそうですよね。
オリジナル画像を機械学習して判定させる様子の動画
本チュートリアルと合わせてご参考ください。
\AIエンジニアに必要なスキルが身に付く/
まとめ
AI や人工知能のニュースを見たり、勉強していると「画像認識ってすごいな、かっこいいな」と思っている方も少なくないと思います。しかしどうでしょう、今回自分のオリジナル画像を機械学習でコンピューターに認識させることができました。これってすごく大きな前進ではないでしょうか?
AI に怯える日々から、 AI を利用して生きる日々、どうでしょう、実際にやってみて。なんか AI 時代もいける気がしてきませんか?
ただ、今回利用したチュートリアルはすこし前のモノで、最新の TensorFlow 2 に対応した Tensorflow For Poets は、再トレーニング後のモデルの出力まで。 Python や TensorFlow、ニューラルネットワークの基礎を知っておかないと、なかなか応用はできませんよね。
また今回は学習済みモデルとして retrained_graph.pb を出力。アプリでこの学習モデルを使うには retrained_graph.lite の TensorFlow Lite 形式のファイルが必要に。当然 Android Studio や XCode など目的のアプリにあった開発環境の知識も必要に。 やることは盛り沢山ですが、少しづつ続けていけばきっと仕事や生活に AI リテラシーが活きてくると思います。
「あ〜、一応 Python や AI の参考書は買ったんだけどな...」「Python、 ニューラルネットワーク、 ???」 という方、こうしている間にもドンドン AI は進化しています。急かすわけではありませんが、今の AI 時代の商機を狙っている社会を考えると、モタモタしている場合ではないかもしれません。
マンツーマンのオンライン・レッスンで定評のある CodeCamp では、 AIリテラシー向けに 「Pythonデータサイエンスコース」 と ITの基礎を学べる 「テクノロジーリテラシー 速習コース」 を運営中。 「どんなことやるんだろう?」「本当にスキルが身につくのかな?」という方、無料体験をご利用下さい。東証一部上場企業のグループ会社である CodeCamp は、体験後、ムリな勧誘等は一切行っていません、安心してご検討下さい。
無料体験、ご興味ある方は 公式ページ よりチェックしてみてくださいね。
余談ですが、今回は再トレーニングでオリジナルの画像を機械学習させました。本記事冒頭に Google Cloud Platform の AutoML Vision の画像も掲載していましたが、学習後のテスト結果は再トレーニングの方が優秀。 AutoML Vision はノンプログラマーでも機械学習できるサービスですが、お金と時間、学習精度をみると。。。プログラミングのスキルがあった方が説得力もありますし、今後の当面続く AI 社会に低コストで馴染めそうですよね。その分、会社やプライベートでも活躍の幅が広がりそうです。
【参考にしたページ】
https://github.com/googlecodelabs/tensorflow-for-poets-2
https://codelabs.developers.google.com/codelabs/tensorflow-for-poets/#0
https://androidkt.com/train-image-classifier/







- この記事を書いた人
- オシママサラ








